Smart Agriculture ›› 2023, Vol. 5 ›› Issue (4): 137-149.doi: 10.12133/j.smartag.SA202310003
• Special Issue--Artificial Intelligence and Robot Technology for Smart Agriculture • Previous Articles Next Articles
WANG Herong1,3,4,5( ), CHEN Yingyi1,3,4,5, CHAI Yingqian1,3,4,5, XU Ling1,3,4,5, YU Huihui2,6()
), CHEN Yingyi1,3,4,5, CHAI Yingqian1,3,4,5, XU Ling1,3,4,5, YU Huihui2,6()
Received:2023-10-07
Online:2023-12-30
Foundation items:National Natural Science Foundation of China(62206021); Beijing Digital Agriculture Innovation Consortium Project(BAIC10-2023)
About author:WANG Herong, E-mail: bdcpro2021@163.com
corresponding author:
WANG Herong, CHEN Yingyi, CHAI Yingqian, XU Ling, YU Huihui. Image Segmentation Method Combined with VoVNetv2 and Shuffle Attention Mechanism for Fish Feeding in Aquaculture[J]. Smart Agriculture, 2023, 5(4): 137-149.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.smartag.net.cn/EN/10.12133/j.smartag.SA202310003
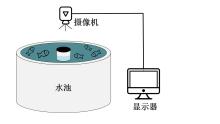
Fig. 1
Structure diagram of image acquisition device
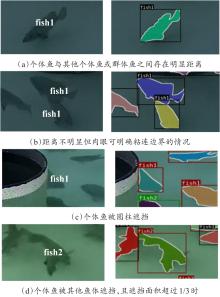
Fig. 2
Example of fish school segmentation dataset labeling
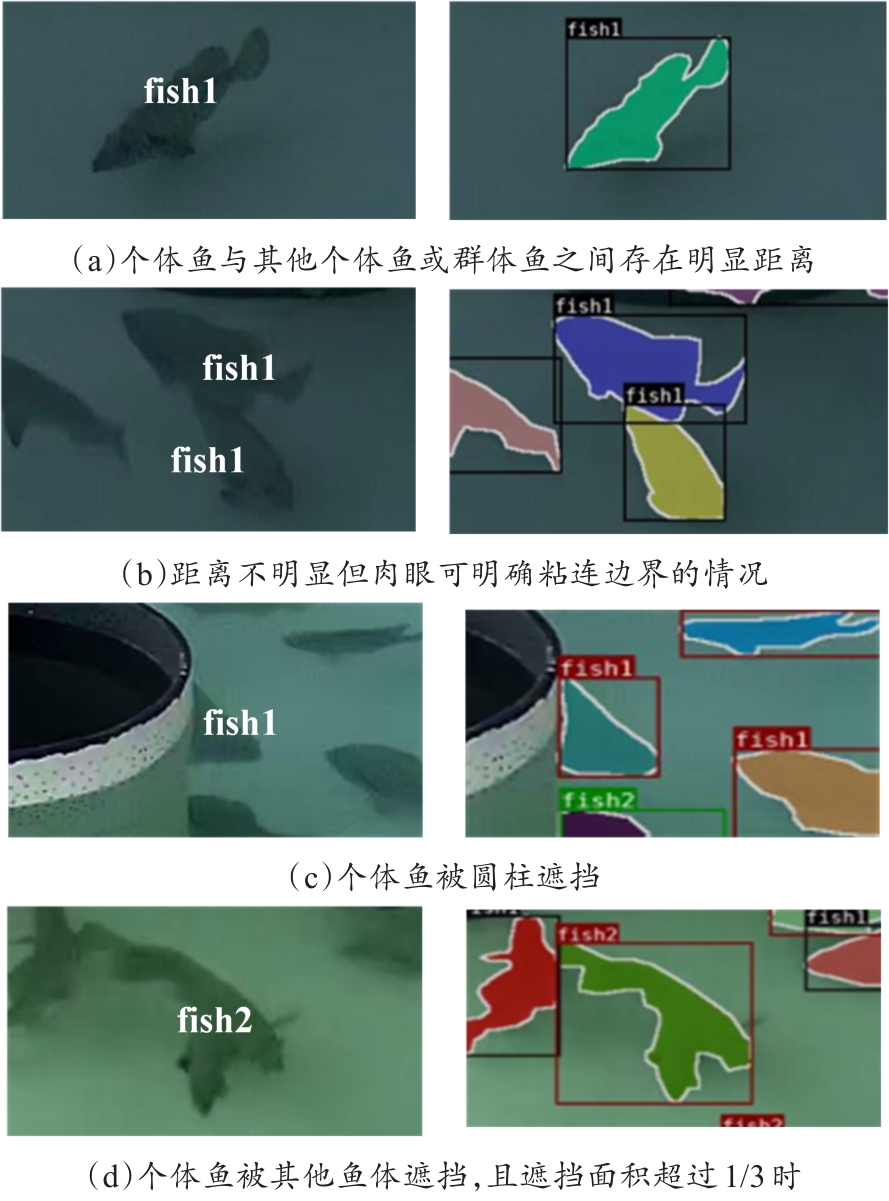

Fig. 3
Example of bad labeling in fish feeding segmentation images

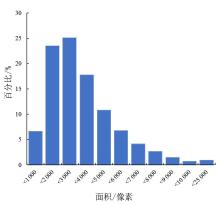
Fig. 4
Statistics of fish school segmentation image target marker area

Fig. 5
Original and data-augmented fish feeding images

Fig. 6
The overall flow chart of fish feeding quantification method
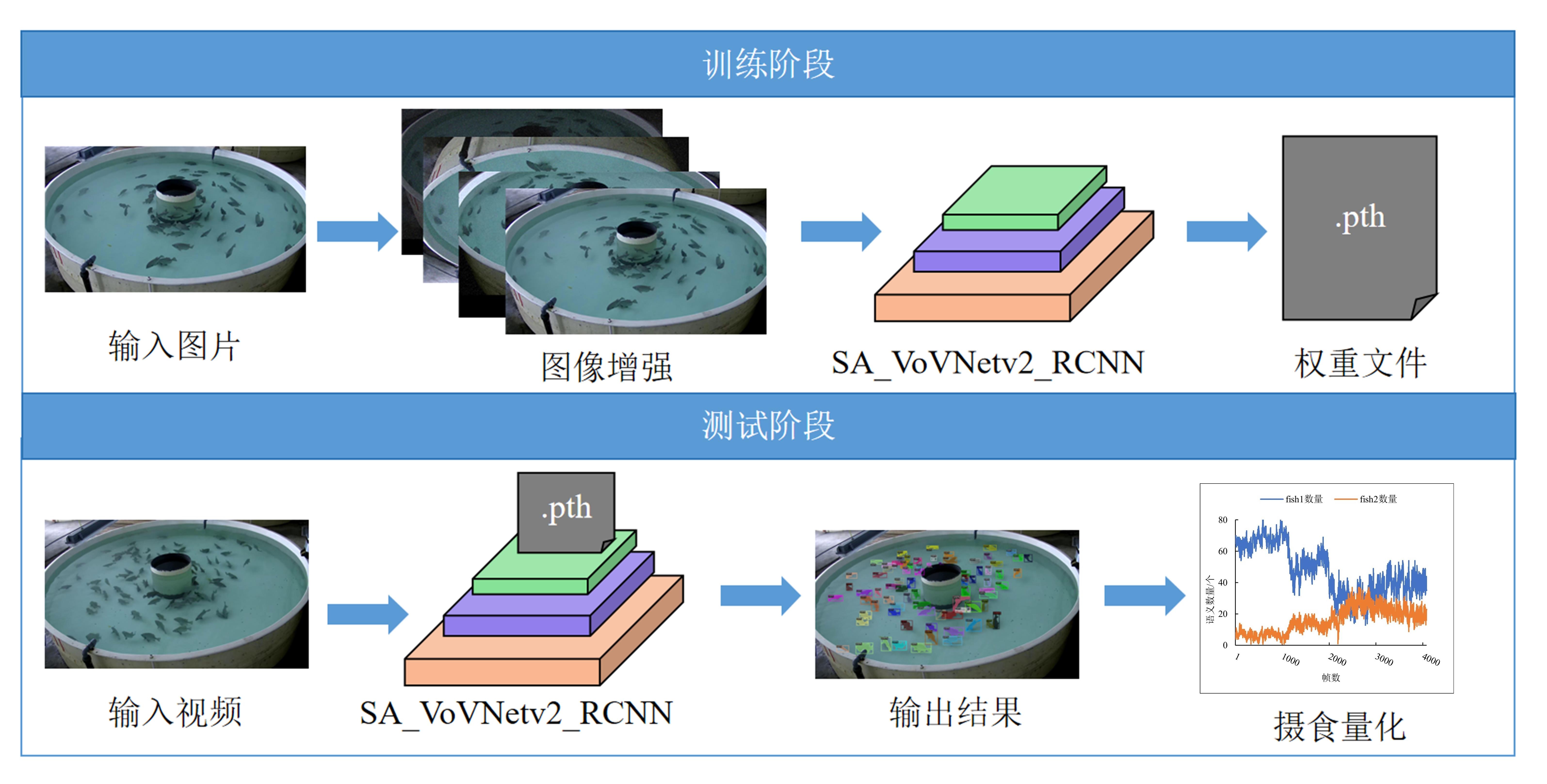
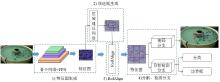
Fig. 7
Structure of Mask R-CNN
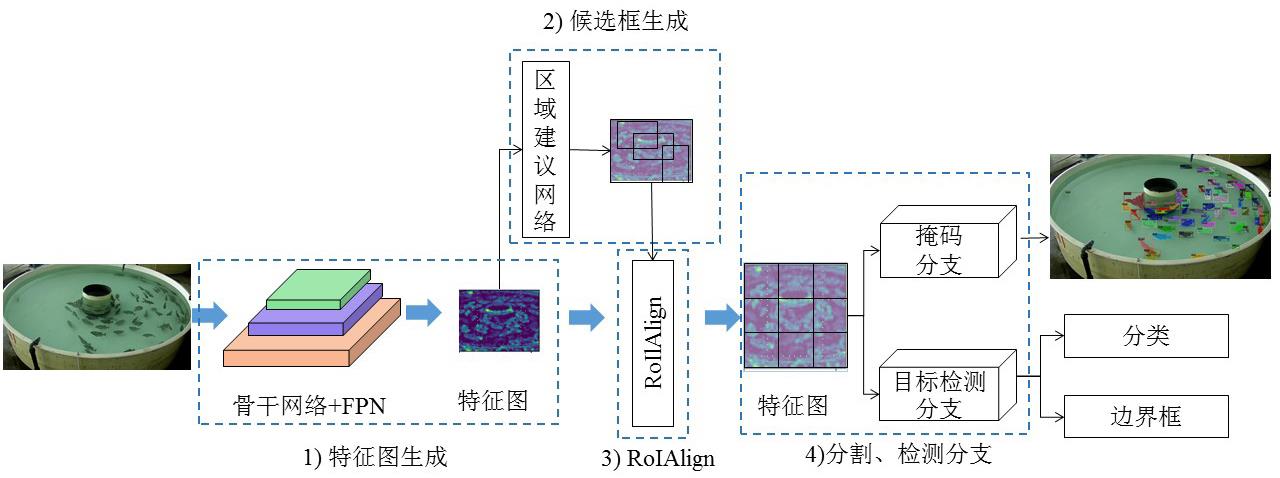
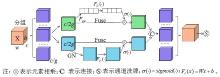
Fig. 8
Structure of shuffle attention
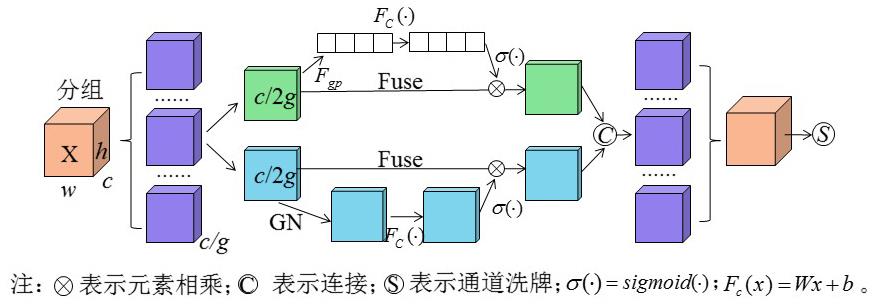
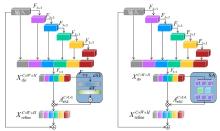
Fig. 9
Structure of the original and improved OSA module
Table 1
The network configuration of VoVNetv2
| 阶段 | VoVNetv2-39 | VoVNetv2-57 | VoVNetv2-99 |
|---|---|---|---|
| 起始 阶段1 |
|
|
|
| OSA模块 阶段2 | |||
| OSA模块 阶段3 | |||
| OSA模块 阶段4 | |||
| OSA模块 阶段5 |
Table 2
Evaluation metric of fish school segmentation
| 指标 | 描述 |
|---|---|
| mAP | IoU=0.5∶0.05∶0.95时的平均精度 |
| AP50 | IoU=0.5 |
| AP75 | IoU=0.75 |
| APs | 小型目标(面积<32²)的AP值 |
| APm | 中型目标(32²<面积<96²)的AP值 |
| Apl | 大型目标(96²<面积)的AP值 |
Table 3
Comparison of fish school segmentation accuracy before and after data preprocess
| 预处理方式 | mAP | AP50 | AP75 | APs | APm | APl |
|---|---|---|---|---|---|---|
| 无 | 56.200 | 79.421 | 67.694 | 29.384 | 57.247 | 62.929 |
| 数据清洗 | 63.218 | 85.584 | 75.698 | 67.920 | 63.628 | 68.854 |
| 数据清洗+增强 | 67.284 | 93.265 | 83.317 | 35.457 | 68.135 | 75.056 |
Table4
Comparison of segmentation results of the improved backbone networks on fish feeding segmentation dataset
| 骨干网络 | mAP | AP50 | AP75 | APs | APm | APl | 参数量/M |
|---|---|---|---|---|---|---|---|
| ResNet50 | 67.284 | 93.265 | 83.317 | 35.457 | 68.135 | 75.056 | 44.3 |
| VoVNetv2-39 | 69.795 | 93.382 | 85.457 | 35.878 | 70.792 | 75.716 | 45.7 |
| VoVNetv2-57 | 70.624 | 93.828 | 86.959 | 37.708 | 71.447 | 77.152 | 62.0 |
| VoVNetv2-99 | 71.580 | 94.151 | 88.369 | 36.168 | 72.363 | 77.860 | 90.0 |
| SA_VoVNetv2-39 | 71.014 | 93.864 | 87.081 | 38.231 | 71.967 | 76.095 | 42.1 |
Table 5
Comparison of segmentation results of different models on fish feeding segmentation dataset
| 网络 | mAP | AP50 | AP75 | APs | APm | APl |
|---|---|---|---|---|---|---|
| SOLOv2 | 52.756 | 85.905 | 63.905 | 16.737 | 53.644 | 69.141 |
| CondInst | 58.946 | 92.196 | 73.463 | 23.803 | 60.100 | 71.053 |
| BlendMask | 67.032 | 93.261 | 82.548 | 34.583 | 67.962 | 76.676 |
| SA_VoVNetv2-39_RCNN | 71.014 | 93.864 | 87.081 | 38.231 | 71.967 | 76.095 |

Fig. 10
Visualized segmentation results for each model on the fish school feeding images

Fig. 11
Loss function of different segmentation models on fish school feeding dataset
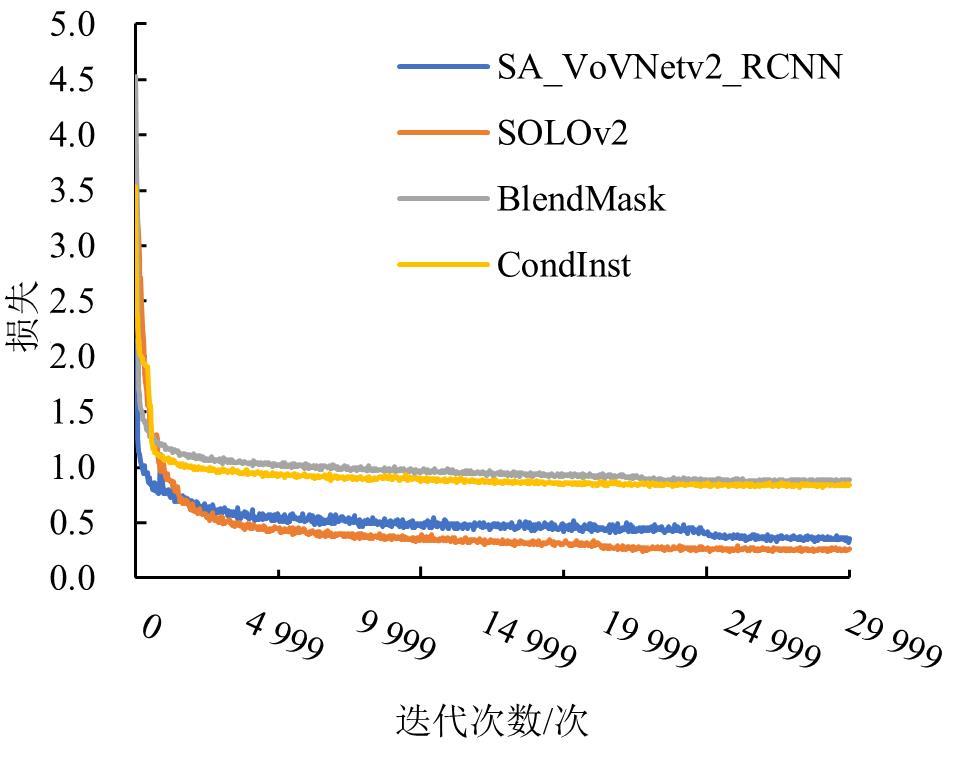

Fig. 12
Error segmentation results on fish school feeding dataset for the improved model (SA_VoVNetv2-39_RCNN)

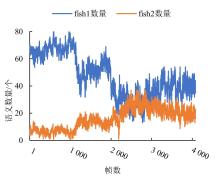
Fig.13
Curve of fish school category change under different feeding states
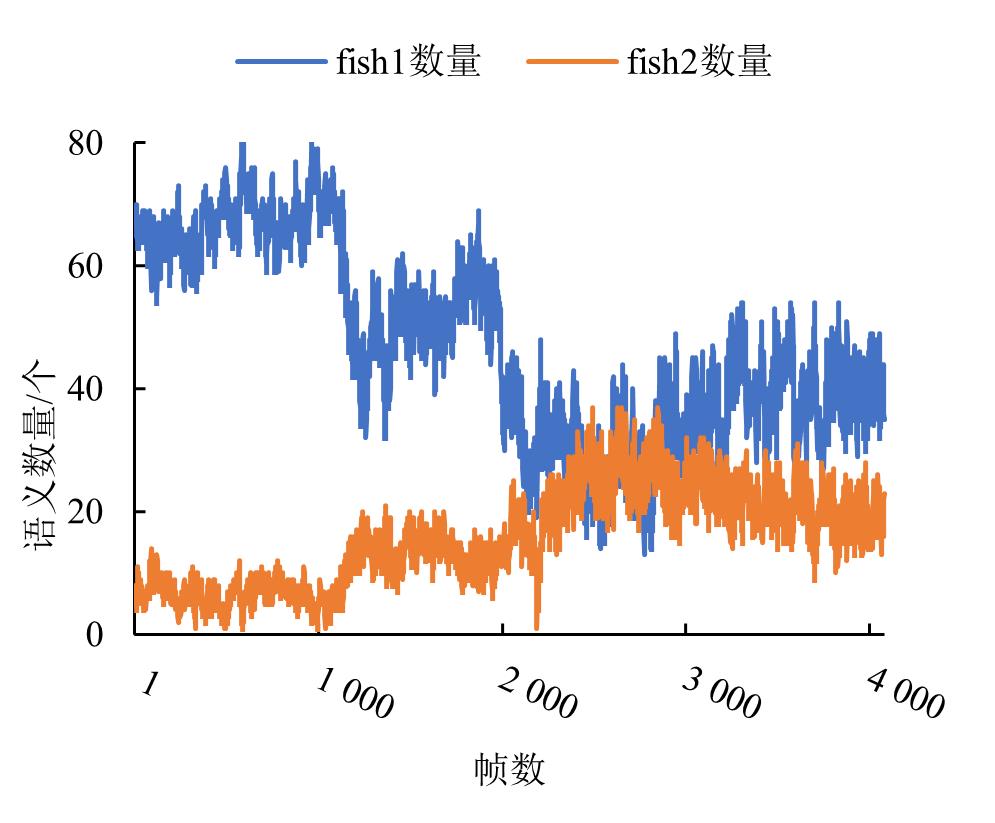
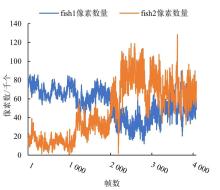
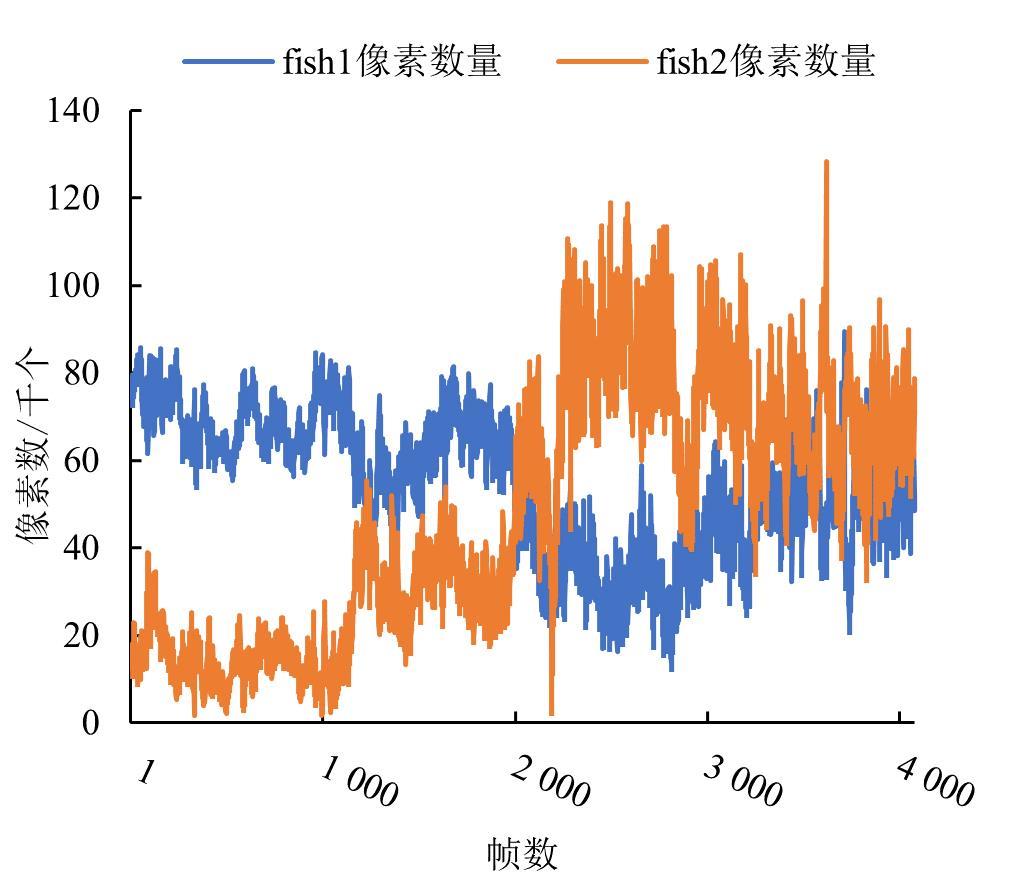
Fig. 14
Curve of fish school pixel change under different feeding states
| 1 |
李道亮, 刘畅. 人工智能在水产养殖中研究应用分析与未来展望[J]. 智慧农业(中英文), 2020, 2(3): 1-20.
|
|
|
|
| 2 |
杨玲. 基于机器视觉的工厂化鱼群摄食行为智能分析方法研究[D]. 北京: 中国农业大学, 2022.
|
|
|
|
| 3 |
|
| 4 |
|
| 5 |
|
| 6 |
|
| 7 |
|
| 8 |
田志新, 廖薇, 茅健, 等. 融合边缘监督的改进Deeplabv3+水下鱼类分割方法[J]. 电子测量与仪器学报, 2022, 36(10): 208-216.
|
|
|
|
| 9 |
|
| 10 |
WOO S,
|
| 11 |
覃学标, 黄冬梅, 宋巍, 等. 基于目标检测及边缘支持的鱼类图像分割方法[J]. 农业机械学报, 2023, 54(1): 280-286.
|
|
|
|
| 12 |
|
| 13 |
|
| 14 |
|
| 15 |
郭奕, 黄佳芯, 邓博奇, 等. 改进Mask R-CNN的真实环境下鱼体语义分割[J]. 农业工程学报, 2022, 38(23): 162-169.
|
|
|
|
| 16 |
|
| 17 |
|
| 18 |
姜波. 基于计算机视觉与深度学习的奶牛跛行检测方法研究[D]. 杨凌: 西北农林科技大学, 2020.
|
|
|
|
| 19 |
|
| 20 |
|
| 21 |
|
| 22 |
|
| 23 |
|
| 24 |
|
| 25 |
|
| 26 |
|
| 27 |
|
| 28 |
|
| 29 |
|
| 30 |
|
| 31 |
|
| [1] | WU Zhangbin, HE Ning, WU Yandong, GUO Xinyu, WEN Weiliang. Point Cloud Data-driven Methods for Estimating Maize Leaf Biomass [J]. Smart Agriculture, 2026, 8(1): 156-166. |
| [2] | HUANG Xianguo, ZHU Qibing, HUANG Min. Online Detection System for Freshness of Fruits and Vegetables Based on Temporal Multi-source Information Fusion [J]. Smart Agriculture, 2026, 8(1): 203-212. |
| [3] | HU Yumeng, GUAN Feifan, XIE Dongchen, MA Ping, YU Youben, ZHOU Jie, NIE Yanming, HUANG Lüwen. Tea Leaf Disease Diagnosis Based on Improved Lightweight U-Net3+ [J]. Smart Agriculture, 2026, 8(1): 15-27. |
| [4] | CAI Yuqin, LIU Daming, XU Qin, LI Boyang, LIU Bojie. Greenhouse Temperature and Humidity Prediction Method Based on Adaptive Kalman Filter and GWO-LSTM-Attention [J]. Smart Agriculture, 2026, 8(1): 148-155. |
| [5] | YAO Xiaotong, QU Shaoye. Lightweight Detection Method for Pepper Leaf Diseases and Pests Based on Improved YOLOv12s [J]. Smart Agriculture, 2026, 8(1): 1-14. |
| [6] | ZHANG Yun, ZHANG Lumin, XU Guangtao, HAO Jiahui. Remote Sensing Extraction Method of Rice-Crayfish Fields Based on Dual-Branch and Multi-Scale Attention [J]. Smart Agriculture, 2025, 7(6): 185-195. |
| [7] | ZHAO Jun, NIE Zhigang, LI Guang, LIU Jiayu. Corn Borer Pests Infestations Detection Method Using Low-Altitude Close-Range UAV Imagery [J]. Smart Agriculture, 2025, 7(6): 111-123. |
| [8] | LI Wenzheng, YANG Xinting, SUN Chuanheng, CUI Tengpeng, WANG Hui, LI Shanshan, LI Wenyong. Light-Trapping Rice Planthopper Detection Method by Combining Spatial Depth Transform Convolution and Multi-scale Attention Mechanism [J]. Smart Agriculture, 2025, 7(5): 169-181. |
| [9] | HAN Wenkai, LI Tao, FENG Qingchun, CHEN Liping. Lightweight Apple Instance Segmentation Algorithm Based on SSW-YOLOv11n for Complex Orchard Environments [J]. Smart Agriculture, 2025, 7(5): 114-123. |
| [10] | WANG Fengyun, WANG Xuanyu, AN Lei, FENG Wenjie. Detection Method for Log-Cultivated Shiitake Mushrooms Based on Improved RT-DETR [J]. Smart Agriculture, 2025, 7(5): 67-77. |
| [11] | ZHAO Yingping, LIANG Jinming, CHEN Beizhang, DENG Xiaoling, ZHANG Yi, XIONG Zheng, PAN Ming, MENG Xiangbao. Applications Research Progress and Prospects of Multi-Agent Large Language Models in Agricultural [J]. Smart Agriculture, 2025, 7(5): 37-51. |
| [12] | LIU Yiheng, LIU Libo. Beef Cattle Object Detection Method Under Occlusion Environment Based on Improved YOLOv12 [J]. Smart Agriculture, 2025, 7(5): 182-192. |
| [13] | HU Yan, WANG Yujie, ZHANG Xuechen, ZHANG Yiqiang, YU Huahao, SONG Xinbei, YE Sitan, ZHOU Jihong, CHEN Zhenlin, ZONG Weiwei, HE Yong, LI Xiaoli. Non-Destructive Inspection and Intelligent Grading Method of Fu Brick Tea at Fungal Fermentation Stage Based on Hyperspectral Imaging Technology [J]. Smart Agriculture, 2025, 7(4): 71-83. |
| [14] | WANG Yi, XUE Rong, HAN Wenting, SHAO Guomin, HOU Yanqiao, CUI Xitong. Estimation of Maize Aboveground Biomass Based on CNN-LSTM-SA [J]. Smart Agriculture, 2025, 7(4): 159-173. |
| [15] | LI Ruijie, WANG Aidong, WU Huaxing, LI Ziqiu, FENG Xiangqian, HONG Weiyuan, TANG Xuejun, QIN Jinhua, WANG Danying, CHU Guang, ZHANG Yunbo, CHEN Song. Remote Sensing for Rice Growth Stages Monitoring: Research Progress, Bottleneck Problems and Technical Optimization Paths [J]. Smart Agriculture, 2025, 7(3): 89-107. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||







