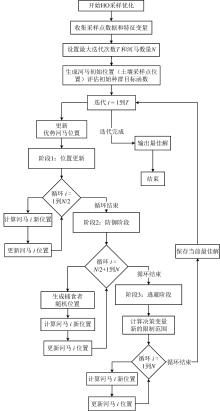
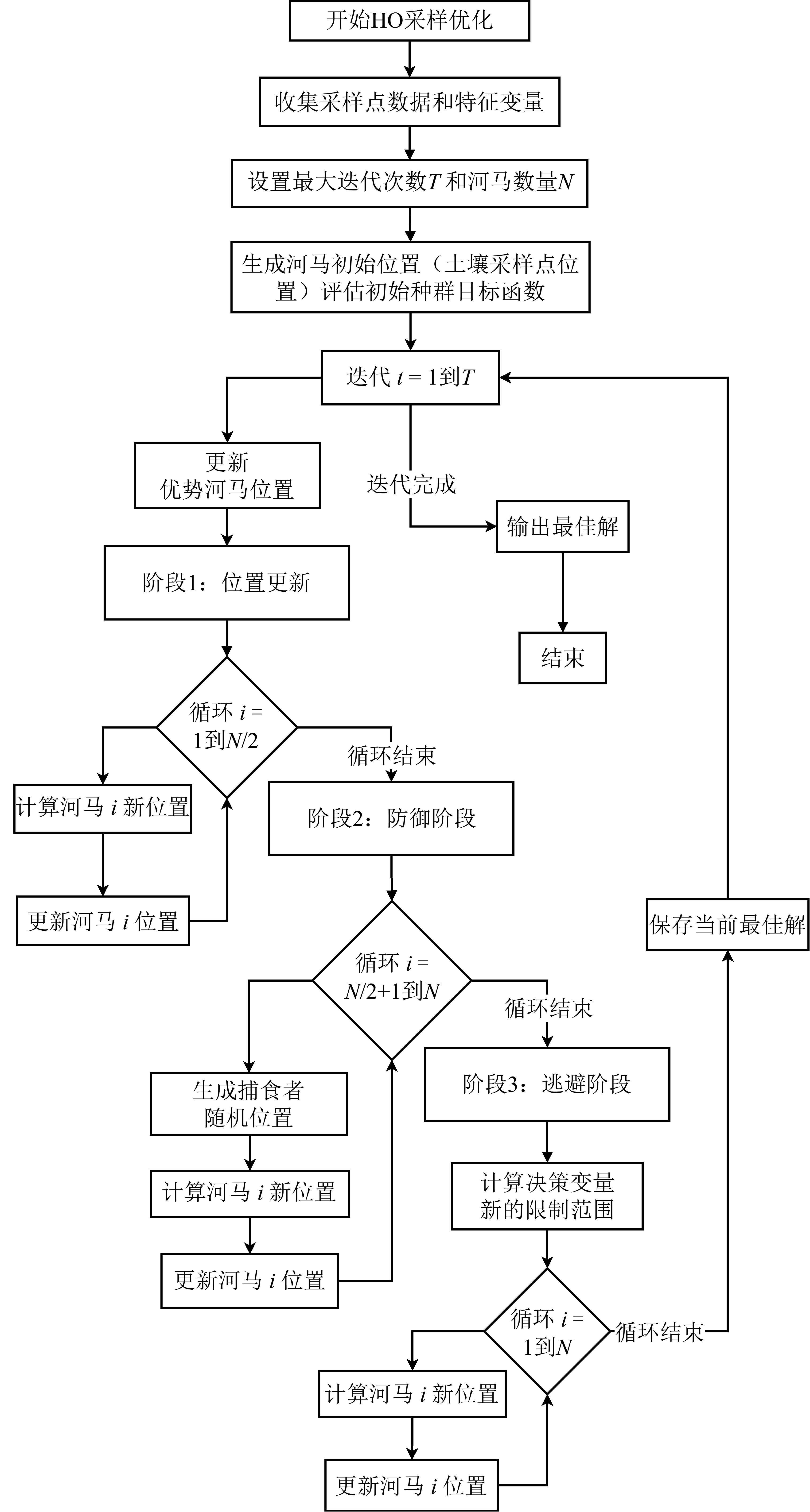
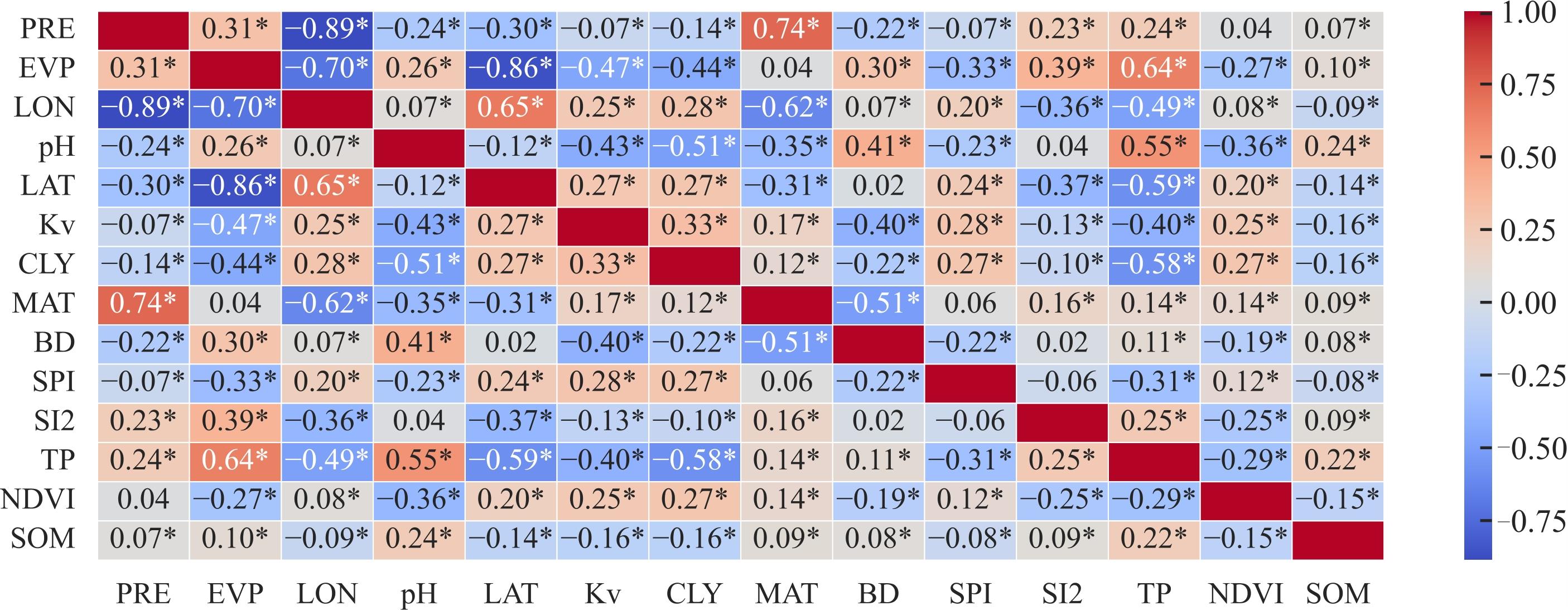
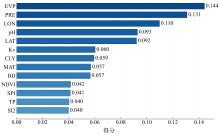
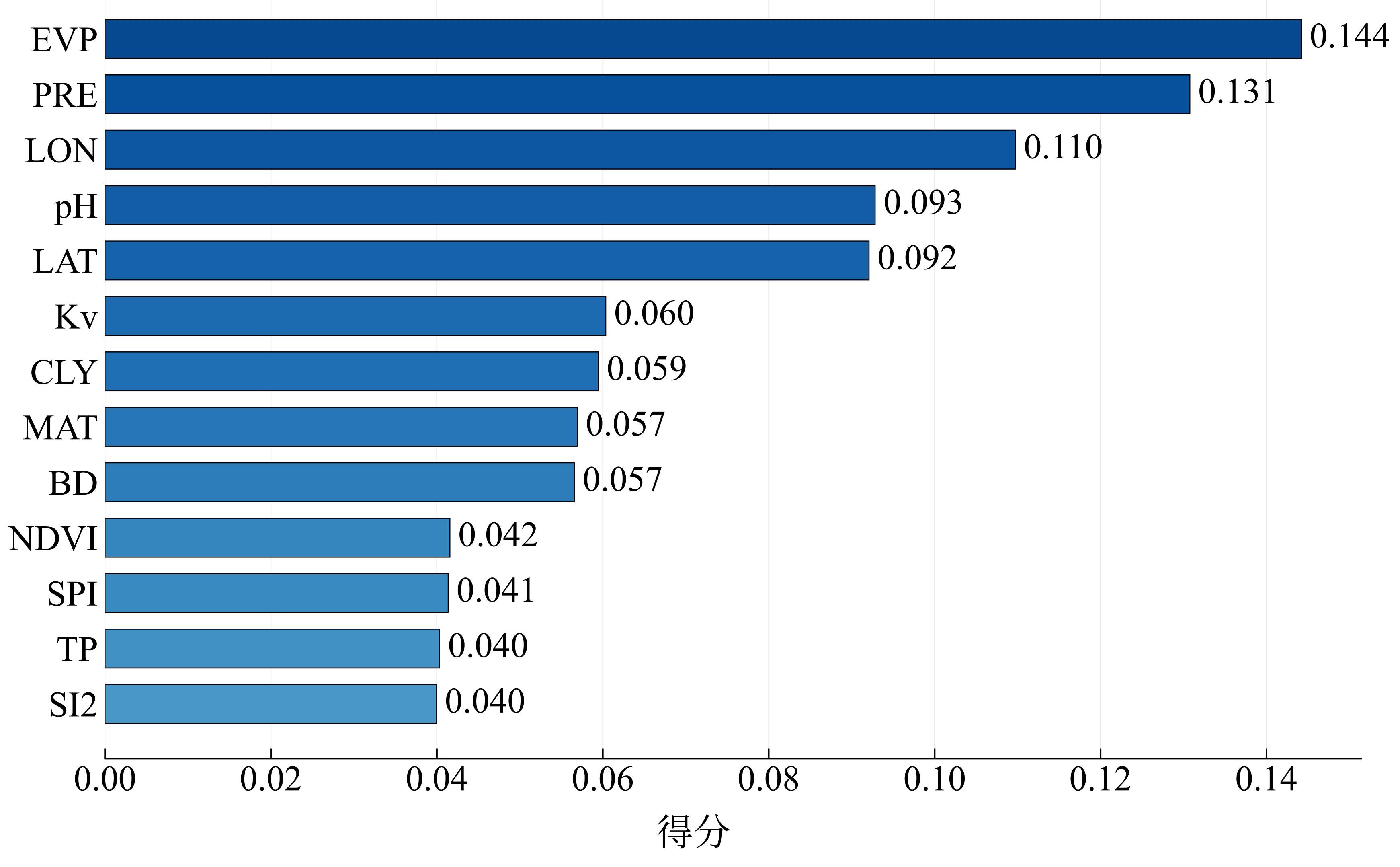
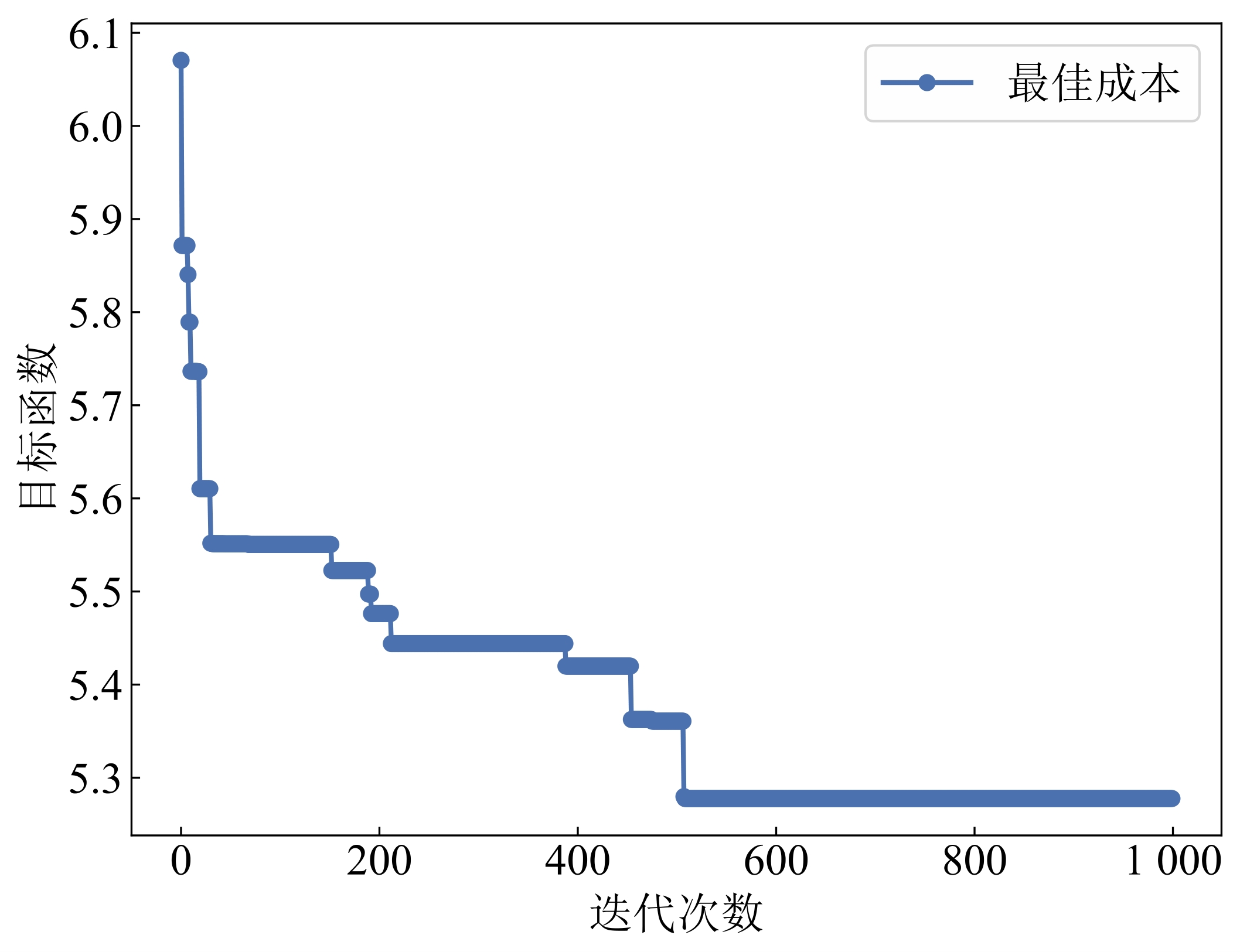
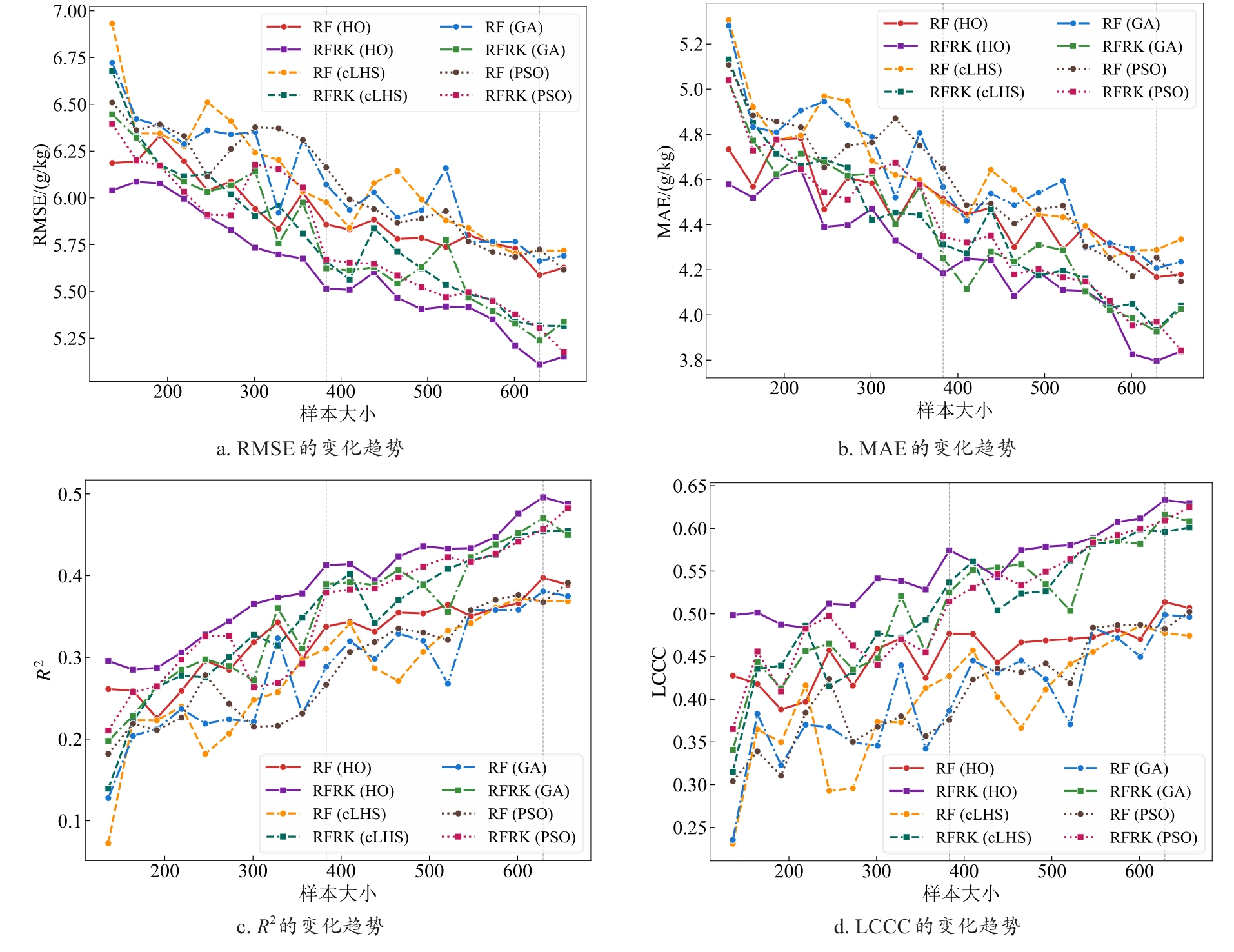
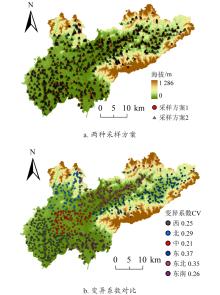
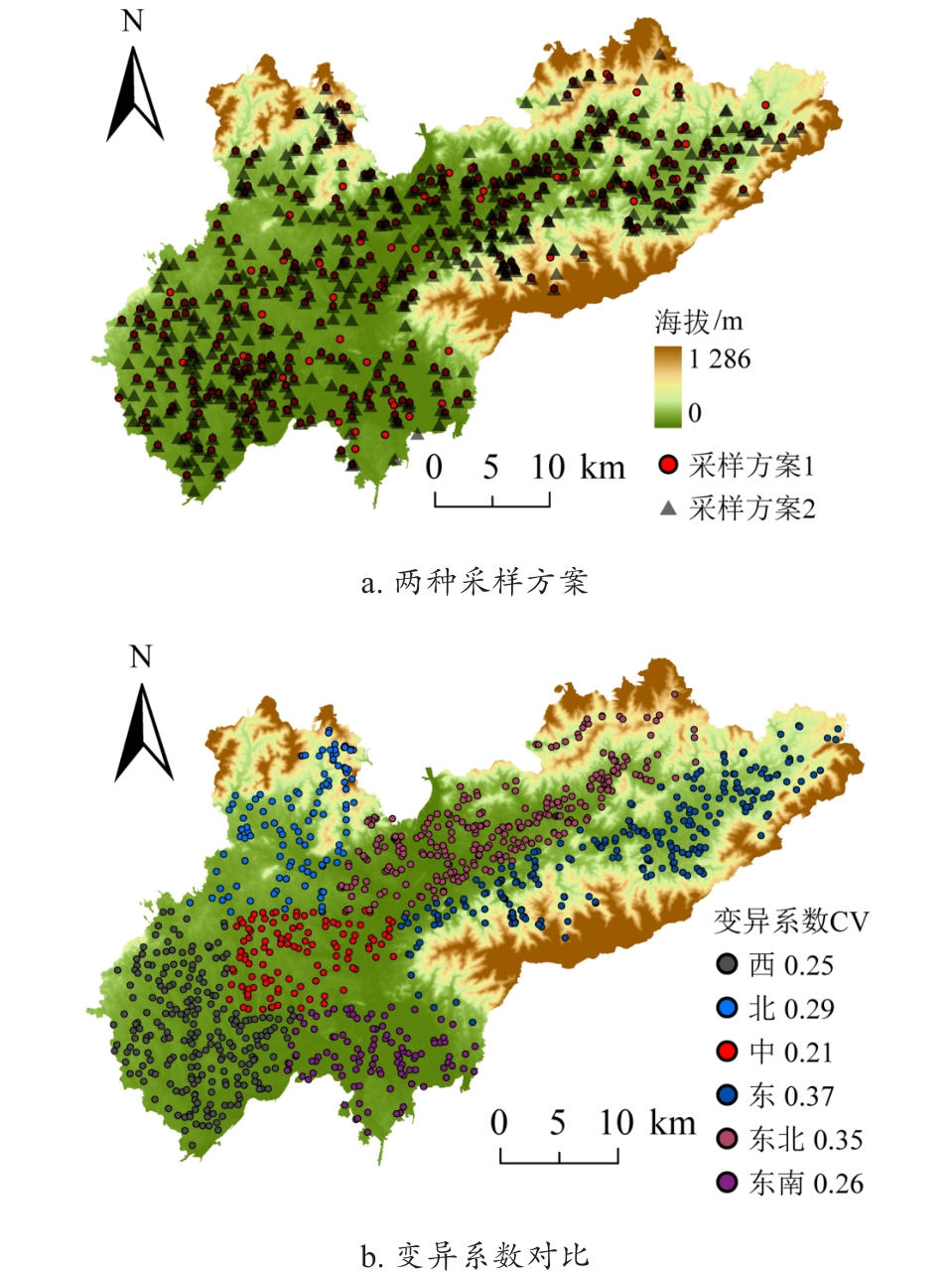
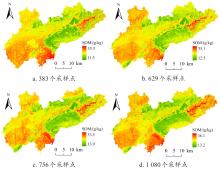
| [1] |
杨贵军, 赵春江, 杨小冬, 等. 粮食生产大数据平台研究进展与展望[J]. 智慧农业(中英文), 2025, 7(2): 1-12.
|
|
YANG G J, ZHAO C J, YANG X D, et al. Grain production big data platform: Progress and prospects[J]. Smart Agriculture, 2025, 7(2): 1-12.
|
| [2] |
何发坤, 蒲生彦, 肖胡萱, 等. 遥感技术在土壤退化中的应用研究进展[J]. 农业资源与环境学报, 2021, 38(1): 10-19.
|
|
HE F K, PU S Y, XIAO H X, et al. Review of remote sensing application in soil degradation[J]. Journal of Agricultural Resources and Environment, 2021, 38(1): 10-19.
|
| [3] |
RADOČAJ D, JUG D, JUG I, et al. A comprehensive evaluation of machine learning algorithms for digital soil organic carbon mapping on a national scale[J]. Applied Sciences, 2024, 14(21): 9990.
|
| [4] |
TOBORE A O, NKWUNONWO U C, ABDUSSALAAM S A, et al. Random forest algorithm and remote sensing techniques for wetland soil organic carbon prediction towards environmental sustainability[J]. Discover Environment, 2025, 3(1): 222.
|
| [5] |
周洋, 赵小敏, 郭熙. 基于多源辅助变量和随机森林模型的表层土壤全氮分布预测[J]. 土壤学报, 2022, 59(2): 451-460.
|
|
ZHOU Y, ZHAO X M, GUO X. Prediction of total nitrogen distribution in surface soil based on multi-source auxiliary variables and random forest approach[J]. Acta Pedologica Sinica, 2022, 59(2): 451-460.
|
| [6] |
BARCA E, DE BENEDETTO D, STELLACCI A M. Optimization of sampling design for soil total organic carbon assessment in the precision agriculture framework: Impact of different variogram models and potentiality of ground penetrating radar (GPR) covariate information[J]. Computers and Electronics in Agriculture, 2024, 226: 109470.
|
| [7] |
ŽÍŽALA D, PRINC T, SKÁLA J, et al. Soil sampling design matters-Enhancing the efficiency of digital soil mapping at the field scale[J]. Geoderma Regional, 2024, 39: e00874.
|
| [8] |
PETROVSKAIA A, GASANOV M, NIKITIN A, et al. Maximizing dataset variability in agricultural surveys with spatial sampling based on MaxVol matrix approximation[J]. Precision Agriculture, 2024, 26(1): 9.
|
| [9] |
黄思华, 濮励杰, 解雪峰, 等. 面向数字土壤制图的土壤采样设计研究进展与展望[J]. 土壤学报, 2020, 57(2): 259-272.
|
|
HUANG S H, PU L J, XIE X F, et al. Review and outlook of designing of soil sampling for digital soil mapping[J]. Acta Pedologica Sinica, 2020, 57(2): 259-272.
|
| [10] |
KHAN A, AITKENHEAD M, STARK C R, et al. Optimal sampling using conditioned Latin hypercube for digital soil mapping: An approach using Bhattacharyya distance[J]. Geoderma, 2023, 439: 116660.
|
| [11] |
SAURETTE D D, BISWAS A, HECK R J, et al. Determining minimum sample size for the conditioned Latin hypercube sampling algorithm[J]. Pedosphere, 2024, 34(3): 530-539.
|
| [12] |
李维友, 段良霞, 谢红霞, 等. 基于条件拉丁超立方抽样的县域耕地土壤有机质空间插值合理样本密度的确定[J]. 土壤通报, 2022, 53(3): 505-513.
|
|
LI W Y, DUAN L X, XIE H X, et al. Determination of reasonable sample density for spatial interpolation of soil organic matter in cultivated land of county region based on conditional Latin hypercube sampling[J]. Chinese Journal of Soil Science, 2022, 53(3): 505-513.
|
| [13] |
MOLLA A, ZUO S D, ZHANG W W, et al. Optimal spatial sampling design for monitoring potentially toxic elements pollution on urban green space soil: A spatial simulated annealing and k-means integrated approach[J]. The Science of the Total Environment, 2022, 802: 149728.
|
| [14] |
SHAO S S, SU B W, ZHANG Y L, et al. Sample design optimization for soil mapping using improved artificial neural networks and simulated annealing[J]. Geoderma, 2022, 413: 115749.
|
| [15] |
DADA B A, NWULU N I, OLUKANMI S O. Bayesian optimization with Optuna for enhanced soil nutrient prediction: A comparative study with genetic algorithm and particle swarm optimization[J]. Smart Agricultural Technology, 2025, 12: 101136.
|
| [16] |
WU X Y, LI Y, WU K N, et al. GA-optimized sampling for soil type mapping in plain areas: Integrating legacy maps and multisource covariates[J]. Agronomy, 2025, 15(4): 963.
|
| [17] |
AMIRI M H, MEHRABI HASHJIN N, MONTAZERI M, et al. Hippopotamus optimization algorithm: A novel nature-inspired optimization algorithm[J]. Scientific Reports, 2024, 14(1): 5032.
|
| [18] |
RUSS A, RIEK W, WESSOLEK G. Three-dimensional mapping of forest soil carbon stocks using SCORPAN modelling and relative depth gradients in the north-eastern Lowlands of Germany[J]. Applied Sciences, 2021, 11(2): 714.
|
| [19] |
SINDHUSHREE T S, KAVYA D, JITENDRA G H, et al. Digital soil mapping: A review of techniques, applications and emerging trends[J]. Journal of Scientific Research and Reports, 2025, 31(7): 1151-1158.
|
| [20] |
ZHANG Y, LUO C, ZHANG W Q, et al. Mapping soil organic matter in black soil cropland areas using remote sensing and environmental covariates[J]. Agriculture, 2025, 15(3): 339.
|
| [21] |
LIU X N, WANG M C, LIU Z W, et al. Improving spatial prediction of soil organic matter in typical black soil area of Northeast China using structural equation modeling integration framework[J]. Computers and Electronics in Agriculture, 2025, 236: 110404.
|
| [22] |
JO Y, PANJA P, KIM H, et al. Soil organic carbon (SOC) prediction using super learner algorithm based on the remote sensing variables[J]. Environmental Challenges, 2025, 19: 101160.
|
| [23] |
李安琪, 杨琳, 蔡言颜, 等. 基于递归特征消除-随机森林模型的江浙沪农田土壤肥力属性制图[J]. 地理科学, 2024, 44(1): 168-178.
|
|
LI A Q, YANG L, CAI Y Y, et al. Digital mapping of soil fertility attributes in croplands in Jiangsu, Zhejiang and Shanghai based on recursive feature elimination-random forest model[J]. Scientia Geographica Sinica, 2024, 44(1): 168-178.
|
| [24] |
郭静, 龙慧灵, 何津, 等. 基于Google Earth Engine和机器学习的耕地土壤有机质含量预测[J]. 农业工程学报, 2022, 38(18): 130-137.
|
|
GUO J, LONG H L, HE J, et al. Predicting soil organic matter contents in cultivated land using Google Earth Engine and machine learning[J]. Transactions of the Chinese Society of Agricultural Engineering, 2022, 38(18): 130-137.
|
| [25] |
张晓婷, 黄魏, 傅佩红, 等. 基于特征筛选算法的数字土壤制图研究[J]. 土壤学报, 2024, 61(3): 635-647.
|
|
ZHANG X T, HUANG W, FU P H, et al. Research on digital soil mapping based on feature selection algorithm[J]. Acta Pedologica Sinica, 2024, 61(3): 635-647.
|
| [26] |
WANG H B, BINTI MANSOR N N, MOKHLIS H B. Novel hybrid optimization technique for solar photovoltaic output prediction using improved Hippopotamus Algorithm[J]. Applied Sciences, 2024, 14(17): 7803.
|
| [27] |
王雨雪, 杨柯, 高秉博, 等. 基于两点机器学习方法的土壤有机质空间分布预测[J]. 农业工程学报, 2022, 38(12): 65-73.
|
|
WANG Y X, YANG K, GAO B B, et al. Prediction of the spatial distribution of soil organic matter based on two-point machine learning method[J]. Transactions of the Chinese Society of Agricultural Engineering, 2022, 38(12): 65-73.
|
| [28] |
HO V H, MORITA H, BACHOFER F, et al. Random forest regression Kriging modeling for soil organic carbon density estimation using multi-source environmental data in central Vietnamese forests[J]. Modeling Earth Systems and Environment, 2024, 10(6): 7137-7158.
|
| [29] |
CHEN Z X, WANG Z, WANG X, et al. Including soil spatial neighbor information for digital soil mapping[J]. Geoderma, 2024, 451: 117072.
|
| [30] |
张世文, 朱曾红, 王维瑞, 等. 基于粒子群-随机森林模型的采样布局优化[J]. 安徽理工大学学报(自然科学版), 2023, 43(6): 37-44.
|
|
ZHANG S W, ZHU Z H, WANG W R, et al. Sample layout optimization based on particle swarm-random forest model[J]. Journal of Anhui University of Science and Technology (Natural Science), 2023, 43(6): 37-44.
|
| [31] |
LIU Y Q, JIANG C L, FENG A P, et al. A causal prediction method for soil organic carbon storage change estimation, with Shaanxi province as a case study[J]. Computers and Electronics in Agriculture, 2025, 234: 110271.
|
| [32] |
徐英, 谢若禹, 沈丽佳, 等. 基于回归克里格法的土壤盐分采样点布局优化[J]. 农业机械学报, 2022, 53(8): 275-282.
|
|
XU Y, XIE R Y, SHEN L J, et al. Layout optimization of soil salt sampling points based on regression Kriging[J]. Transactions of the Chinese Society for Agricultural Machinery, 2022, 53(8): 275-282.
|
 )
)