Smart Agriculture ›› 2025, Vol. 7 ›› Issue (1): 44-56.doi: 10.12133/j.smartag.SA202410022
• Topic--Intelligent Agricultural Knowledge Services and Smart Unmanned Farms (Part 2) • Previous Articles Next Articles
QI Zijun1, NIU Dangdang1( ), WU Huarui2,3,4, ZHANG Lilin1, WANG Lunfeng1, ZHANG Hongming1()
), WU Huarui2,3,4, ZHANG Lilin1, WANG Lunfeng1, ZHANG Hongming1()
Received:2024-10-20
Online:2025-01-30
Foundation items:Shaanxi Province Qin Chuang Yuan "Scientist + Engineer" Team Building Project(2022KXJ-67); National Natural Science Foundation of China(62206222)
About author:QI Zijun, E-mail: qilaoban666@gmail.com
corresponding author:
CLC Number:
QI Zijun, NIU Dangdang, WU Huarui, ZHANG Lilin, WANG Lunfeng, ZHANG Hongming. Chinese Kiwifruit Text Named Entity Recognition Method Based on Dual-Dimensional Information and Pruning[J]. Smart Agriculture, 2025, 7(1): 44-56.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.smartag.net.cn/EN/10.12133/j.smartag.SA202410022
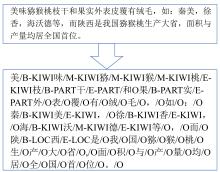
Fig. 1
Multi-level annotation example for named entity recognition in Chinese kiwifruit texts

Table 1
Information statistics table of KIWIPRO for named entity recognition in Chinese kiwifruit texts
| 类别标签(释义) | 类别 | 类别定义 | 示例 | 实体数量/个 |
|---|---|---|---|---|
| KIWI(Variety) | 品种 | 不同品种的猕猴桃名称 | 中华猕猴桃(Chinese kiwifruit) | 3 821 |
| DIS(Disease) | 病害 | 猕猴桃容易遭受的病害 | 软腐病(soft rot) | 1 402 |
| PEST(Insect Pest) | 虫害 | 猕猴桃容易遭受的虫害 | 蝙蝠蛾(Hawk moth) | 1 320 |
| PART(Part) | 部位 | 猕猴桃易受病害侵扰的部位 | 果实(Fruit) | 5 489 |
| MED(Pesticide) | 农药 | 处理猕猴桃病害的药剂 | 多菌灵(Carbendazim) | 1 394 |
| LOC(Location) | 位置 | 不同品种猕猴桃的产地 | 陕西 (Shaanxi) | 4 094 |
| COL(Color) | 颜色 | 猕猴桃果肉颜色 | 红色(red),绿色(green) | 1 268 |
| TAS(Taste) | 口感 | 猕猴桃果肉口感 | 酸(Sour),甜(Sweet) | 892 |
| SHA(Shape) | 形状 | 猕猴桃果实形状 | 椭圆形(Elliptical) | 168 |
| NUT(Nutritional) | 营养成分 | 猕猴桃果实所含营养成分 | 维生素C(Vitamin C) | 325 |
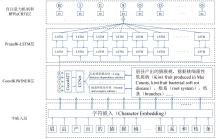
Fig. 2
Architecture of KIWI-Coord-Prune model

Table 2
Hyper-parameter settings for NER in Chinese kiwifruit texts
| 参数名称 | 取值 | 参数名称 | 取值 |
|---|---|---|---|
| 字符向量维度 | 50 | 词典向量维度 | 50 |
| 批大小 | 16 | epoch 数 | 70 |
| 学习率 | 0.008 | Dropout 率 | 0.5 |
| 学习率衰减 | 0.05 | Prune LSTM 隐藏层大小 | 200 |
Table. 3
Experimental environment setup for NER in Chinese kiwifruit texts
| 实验环境 | 配置参数 |
|---|---|
| 操作系统 | Windows 11(x64) |
| CPU | 英特尔 酷睿i9-13900H |
| GPU | NVIDIA GeForce RTX4060(8 GB) |
| 内存 | 64 GB |
| 硬盘 | 2 T |
| Python版本 | 3.7.16 |
| Pytorch版本 | 1.8.1 |
Table. 4
Comparative experimental results of the KIWI-Coord-Prune model on the KIWIDPRO dataset
| 模型 | P/% | R/% | F 1/% |
|---|---|---|---|
| LSTM | 74.85 | 79.86 | 77.27 |
| Bi-LSTM | 81.43 | 89.59 | 85.31 |
| LR-CNN | 86.36 | 90.86 | 88.55 |
| Softlexicon-LSTM | 85.84 | 90.26 | 87.99 |
| KIWINER | 87.09 | 90.47 | 88.75 |
| | 87.27 | 91.95 | 89.55 |
Table. 5
Comparative experimental results of the KIWI-Coord-Prune model on the People's Daily dataset
| 模型 | P/% | R/% | F 1/% |
|---|---|---|---|
| LSTM | 80.53 | 75.36 | 77.86 |
| Bi-LSTM | 85.75 | 80.67 | 83.13 |
| LR-CNN | 90.25 | 89.42 | 89.83 |
| Softlexicon-LSTM | 89.78 | 87.50 | 88.63 |
| KIWINER | 91.13 | 90.74 | 90.93 |
| | 91.96 | 90.09 | 91.02 |
Table. 6
Comparative experimental results of the KIWI-Coord-Prune model on the ClueNER dataset
| 模型 | P/% | R/% | F 1/% |
|---|---|---|---|
| LSTM | 71.99 | 73.09 | 72.54 |
| Bi-LSTM | 76.84 | 78.13 | 77.48 |
| LR-CNN | 82.13 | 84.15 | 83.13 |
| Softlexicon-LSTM | 77.39 | 81.72 | 79.49 |
| KIWINER | 81.05 | 80.01 | 80.52 |
| | 82.86 | 84.15 | 83.50 |
Table 7
Comparative experimental results of the KIWI-Coord-Prune model on the Boson dataset
| 模型 | P/% | R/% | F 1/% |
|---|---|---|---|
| LSTM | 76.16 | 68.85 | 72.32 |
| Bi-LSTM | 81.78 | 72.50 | 76.86 |
| LR-CNN | 79.45 | 81.51 | 80.47 |
| Softlexicon-LSTM | 85.12 | 80.06 | 82.51 |
| KIWINER | 84.40 | 82.40 | 83.39 |
| | 82.74 | 84.26 | 83.49 |
Table 8
Comparative experimental results of the KIWI-Coord-Prune model on the ResumeNER dataset
| 模型 | P/% | R/% | F 1/% |
|---|---|---|---|
| LSTM | 85.41 | 82.32 | 83.84 |
| Bi-LSTM | 92.32 | 91.42 | 91.87 |
| LR-CNN | 95.37 | 94.84 | 95.11 |
| Softlexicon-LSTM | 95.30 | 95.77 | 95.53 |
| KIWINER | 95.58 | 95.11 | 95.34 |
| | 95.69 | 95.93 | 95.81 |

Fig.3
Ablation and comparative experimental results of the CoordKIWINER and the PruneBi-LSTM module
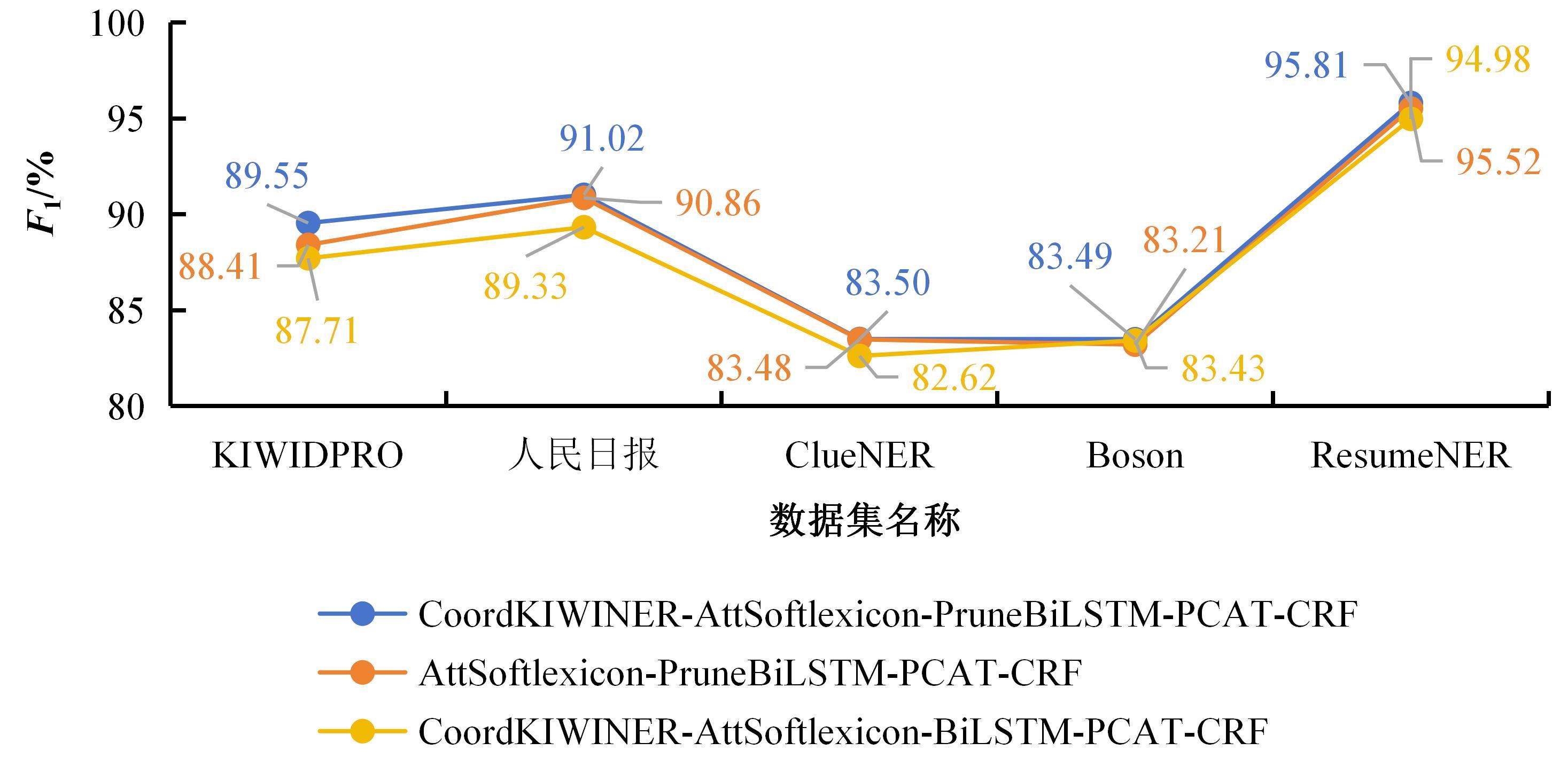
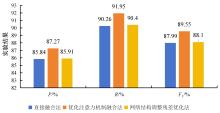
Fig. 4
Comparison of experimental results for three different CoordKIWINER module design methods
Table 9
Comparative analysis of recognition performance of different models on various kiwifruit entity categories
| 类别标签 | 类别 | LSTM | Bi-LSTM | LR-CNN | Softlexicon-LSTM | KIWINER | |
|---|---|---|---|---|---|---|---|
| KIWI | 品种 | 79.57 | 80.01 | 83.73 | 84.15 | 85.64 | 85.88 |
| DIS | 病害 | 75.32 | 76.52 | 81.16 | 86.04 | 87.39 | 88.03 |
| PEST | 虫害 | 77.56 | 78.91 | 83.67 | 85.75 | 88.06 | 88.54 |
| PART | 部位 | 80.63 | 86.21 | 89.28 | 91.66 | 93.25 | 95.32 |
| MED | 农药 | 75.12 | 76.13 | 78.39 | 79.96 | 80.34 | 81.03 |
| LOC | 位置 | 75.03 | 80.12 | 83.43 | 86.32 | 88.41 | 89.76 |
| | | 81.91 | 82.51 | 85.98 | 88.06 | 89.54 | 90.11 |
| | | 77.24 | 82.02 | 84.44 | 84.96 | 87.20 | 88.65 |
| | | 79.88 | 82.80 | 85.82 | 88.57 | 91.13 | 91.28 |
| | | 75.32 | 76.96 | 79.15 | 81.24 | 83.67 | 83.72 |
| 1 |
齐秀娟, 郭丹丹, 王然, 等. 我国猕猴桃产业发展现状及对策建议[J]. 果树学报, 2020, 37(5): 754-763.
|
|
|
|
| 2 |
计洁, 金洲, 王儒敬, 等. 基于递进式卷积网络的农业命名实体识别方法[J]. 智慧农业(中英文), 2023, 5 (1): 122-131.
|
|
|
|
| 3 |
|
| 4 |
|
| 5 |
|
| 6 |
|
| 7 |
张善文, 王振, 王祖良. 结合知识图谱与双向长短时记忆网络的小麦条锈病预测[J]. 农业工程学报, 2020, 36(12): 172-178.
|
|
|
|
| 8 |
刘浏, 王东波. 命名实体识别研究综述[J]. 情报学报, 2018, 37(3): 329-340.
|
|
|
|
| 9 |
赵继贵, 钱育蓉, 王魁, 等. 中文命名实体识别研究综述[J]. 计算机工程与应用, 2024, 60(1): 15-27.
|
|
|
|
| 10 |
杜晋华, 尹浩, 冯嵩. 中文电子病历命名实体识别的研究与进展[J]. 电子学报, 2022, 50(12): 3030-3053.
|
|
|
|
| 11 |
陈婕卿, 竹志超, 张锋, 等. 中文电子病历命名实体识别方法研究[J]. 医学信息学杂志, 2024, 45(4): 78-84.
|
|
|
|
| 12 |
|
| 13 |
张文东, 吴子炜, 宋国昌, 等. 基于SiKuBERT与多元数据嵌入的中医古籍命名实体识别[J]. 华南理工大学学报(自然科学版), 2024, 52(6): 128-137.
|
|
|
|
| 14 |
聂啸林, 张礼麟, 牛当当, 等. 面向葡萄知识图谱构建的多特征融合命名实体识别[J]. 农业工程学报, 2024, 40(3): 201-210.
|
|
|
|
| 15 |
毕达天, 张雪, 孔婧媛, 等. 基于异质图注意力网络与多特征融合的跨社交媒体用户识别研究[J]. 情报学报, 2024, 43(10): 1213-1226.
|
|
|
|
| 16 |
|
| 17 |
|
| 18 |
李书琴, 张明美, 刘斌. 融合字词语义信息的猕猴桃种植领域命名实体识别研究[J]. 农业机械学报, 2022, 53(12): 323-331.
|
|
|
|
| 19 |
|
| 20 |
季源泽, 李霏. CMNER: 基于微博的中文多模态实体识别数据集[J]. 计算机技术与发展, 2024, 34(10): 110-117.
|
|
|
|
| 21 |
|
| 22 |
|
| 23 |
|
| 24 |
|
| 25 |
张宏鸣, 齐梓均, 赵春江, 等. 一种考虑双维信息的中文猕猴桃文本命名实体识别方法: CN202410434428.0[P]. 2024-07-12.
|
| 26 |
|
| 27 |
|
| 28 |
|
| 29 |
|
| 30 |
|
| 31 |
|
| 32 |
|
| 33 |
|
| 34 |
|
| 35 |
|
| 36 |
|
| [1] | WU Zhangbin, HE Ning, WU Yandong, GUO Xinyu, WEN Weiliang. Point Cloud Data-driven Methods for Estimating Maize Leaf Biomass [J]. Smart Agriculture, 2026, 8(1): 156-166. |
| [2] | YAO Xiaotong, QU Shaoye. Lightweight Detection Method for Pepper Leaf Diseases and Pests Based on Improved YOLOv12s [J]. Smart Agriculture, 2026, 8(1): 1-14. |
| [3] | ZHANG Yun, ZHANG Lumin, XU Guangtao, HAO Jiahui. Remote Sensing Extraction Method of Rice-Crayfish Fields Based on Dual-Branch and Multi-Scale Attention [J]. Smart Agriculture, 2025, 7(6): 185-195. |
| [4] | ZHAO Jun, NIE Zhigang, LI Guang, LIU Jiayu. Corn Borer Pests Infestations Detection Method Using Low-Altitude Close-Range UAV Imagery [J]. Smart Agriculture, 2025, 7(6): 111-123. |
| [5] | LI Wenzheng, YANG Xinting, SUN Chuanheng, CUI Tengpeng, WANG Hui, LI Shanshan, LI Wenyong. Light-Trapping Rice Planthopper Detection Method by Combining Spatial Depth Transform Convolution and Multi-scale Attention Mechanism [J]. Smart Agriculture, 2025, 7(5): 169-181. |
| [6] | HAN Wenkai, LI Tao, FENG Qingchun, CHEN Liping. Lightweight Apple Instance Segmentation Algorithm Based on SSW-YOLOv11n for Complex Orchard Environments [J]. Smart Agriculture, 2025, 7(5): 114-123. |
| [7] | WANG Fengyun, WANG Xuanyu, AN Lei, FENG Wenjie. Detection Method for Log-Cultivated Shiitake Mushrooms Based on Improved RT-DETR [J]. Smart Agriculture, 2025, 7(5): 67-77. |
| [8] | GAO Chenhong, ZHU Qibing, HUANG Min. Embedded Fluorescence Imaging Detection System for Fruit and Vegetable Quality Deterioration Based on Improved YOLOv8 [J]. Smart Agriculture, 2025, 7(5): 146-155. |
| [9] | ZHAO Yingping, LIANG Jinming, CHEN Beizhang, DENG Xiaoling, ZHANG Yi, XIONG Zheng, PAN Ming, MENG Xiangbao. Applications Research Progress and Prospects of Multi-Agent Large Language Models in Agricultural [J]. Smart Agriculture, 2025, 7(5): 37-51. |
| [10] | HU Yan, WANG Yujie, ZHANG Xuechen, ZHANG Yiqiang, YU Huahao, SONG Xinbei, YE Sitan, ZHOU Jihong, CHEN Zhenlin, ZONG Weiwei, HE Yong, LI Xiaoli. Non-Destructive Inspection and Intelligent Grading Method of Fu Brick Tea at Fungal Fermentation Stage Based on Hyperspectral Imaging Technology [J]. Smart Agriculture, 2025, 7(4): 71-83. |
| [11] | LI Ruijie, WANG Aidong, WU Huaxing, LI Ziqiu, FENG Xiangqian, HONG Weiyuan, TANG Xuejun, QIN Jinhua, WANG Danying, CHU Guang, ZHANG Yunbo, CHEN Song. Remote Sensing for Rice Growth Stages Monitoring: Research Progress, Bottleneck Problems and Technical Optimization Paths [J]. Smart Agriculture, 2025, 7(3): 89-107. |
| [12] | HAN Yu, QI Kangkang, ZHENG Jiye, LI Jinai, JIANG Fugui, ZHANG Xianglun, YOU Wei, ZHANG Xia. Lightweight Cattle Facial Recognition Method Based on Improved YOLOv11 [J]. Smart Agriculture, 2025, 7(3): 173-184. |
| [13] | LIU Long, WANG Ning, WANG Jiacheng, CAO Yuheng, ZHANG Kai, KANG Feng, WANG Yaxiong. Pruning Point Recognition and Localization for Spindle-Shaped Apple Trees During Dormant Season Using an Improved U-Net Model [J]. Smart Agriculture, 2025, 7(3): 120-130. |
| [14] | MA Liu, MAO Kebiao, GUO Zhonghua. Defogging Remote Sensing Images Method Based on a Hybrid Attention-Based Generative Adversarial Network [J]. Smart Agriculture, 2025, 7(2): 172-182. |
| [15] | XU Shiwei, LI Qianchuan, LUAN Rupeng, ZHUANG Jiayu, LIU Jiajia, XIONG Lu. Agricultural Market Monitoring and Early Warning: An Integrated Forecasting Approach Based on Deep Learning [J]. Smart Agriculture, 2025, 7(1): 57-69. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||







