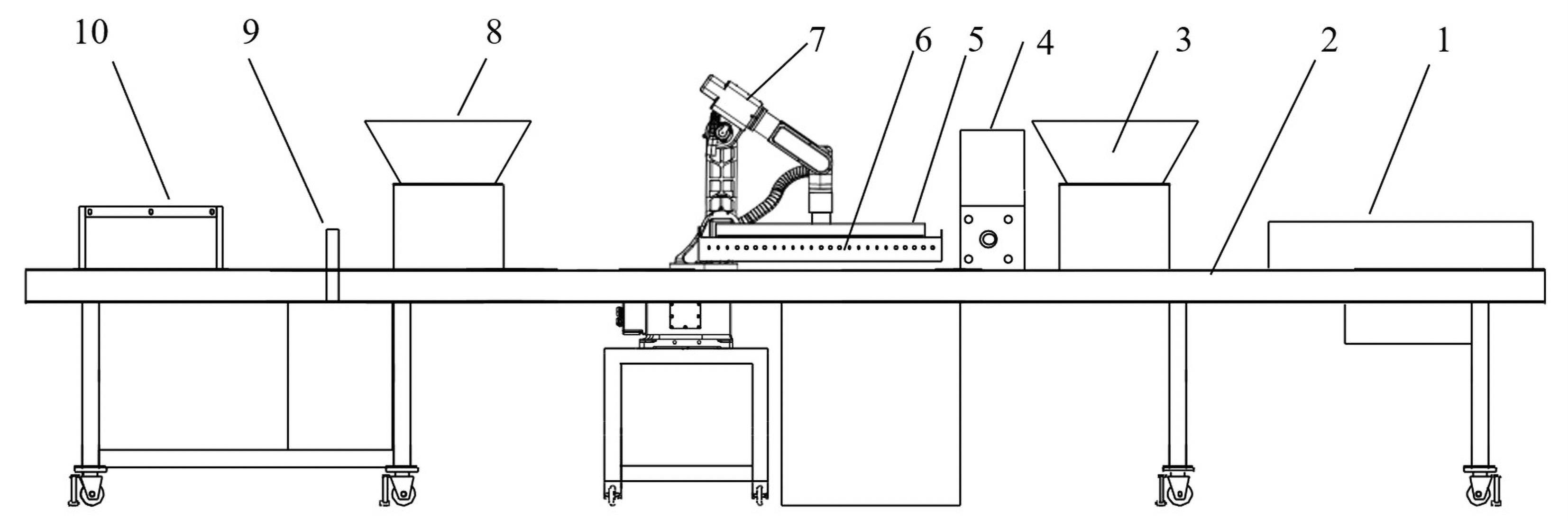
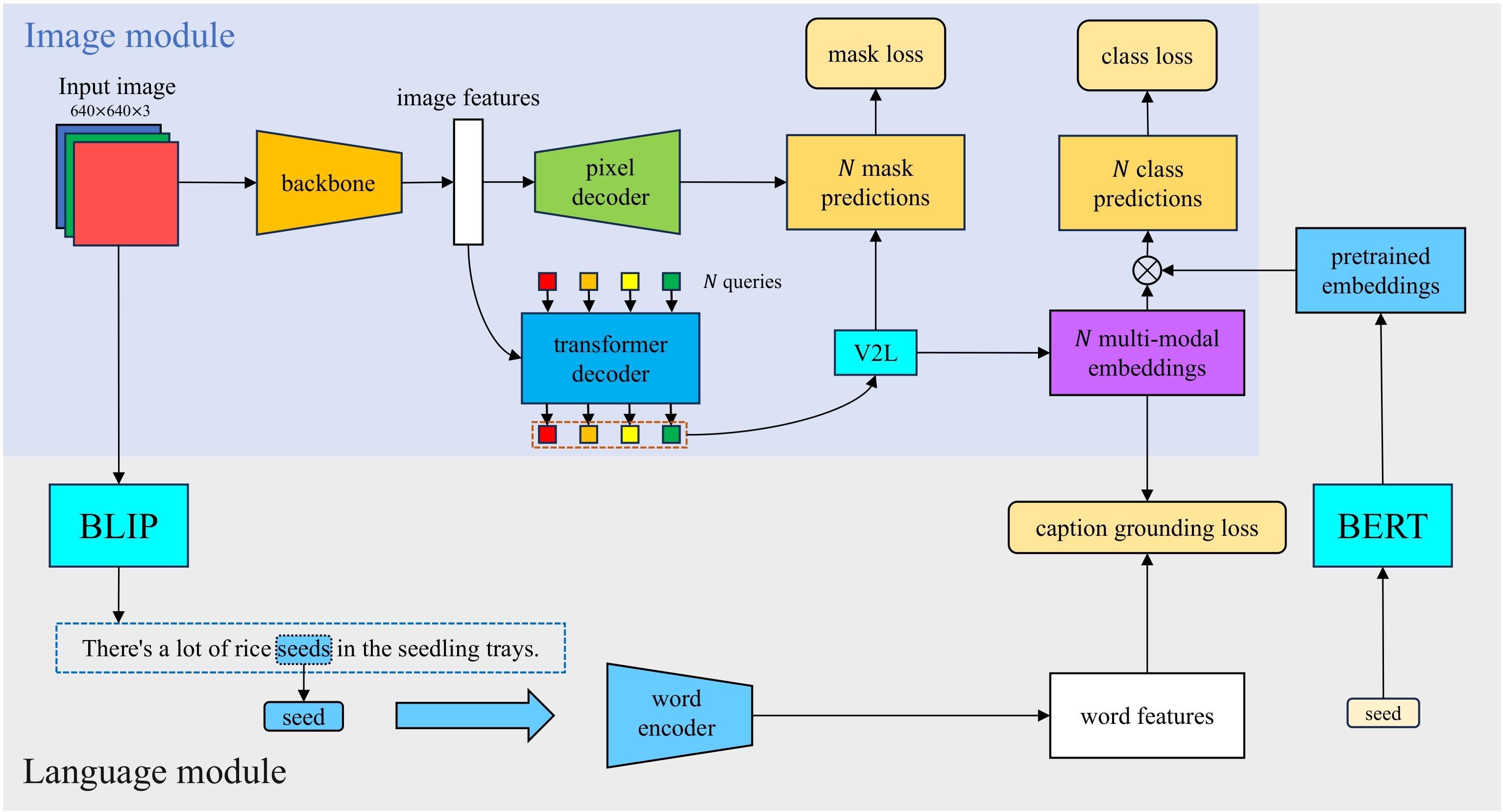
| [1] |
陈品, 徐春春, 纪龙, 等. 2024年我国水稻产业形势分析及2025年展望[J]. 中国稻米, 2025, 31(2): 1-5.
|
|
CHEN P, XU C C, JI L, et al. Analysis of China's rice industry in 2024 and the outlook for 2025[J]. China Rice, 2025, 31(2): 1-5.
|
| [2] |
CHENG J H, LI Y M, CHEN J, et al. Design and realization of seeding quality monitoring system for air-suction vibrating disc type seed meter[J]. Processes, 2022, 10(9): 1745.
|
| [3] |
丁幼春, 王凯阳, 刘晓东, 等. 中小粒径种子播种检测技术研究进展[J]. 农业工程学报, 2021, 37(8): 30-41.
|
|
DING Y C, WANG K Y, LIU X D, et al. Research progress of seeding detection technology for medium and small- size seeds[J]. Transactions of the Chinese Society of Agricultural Engineering, 2021, 37(8): 30-41.
|
| [4] |
DONG W H, MA X, LI H W, et al. Detection of performance of hybrid rice pot-tray sowing utilizing machine vision and machine learning approach[J]. Sensors, 2019, 19(23): 5332.
|
| [5] |
BAI J Q, HAO F Q, CHENG G H, et al. Machine vision-based supplemental seeding device for plug seedling of sweet corn[J]. Computers and Electronics in Agriculture, 2021, 188: 106345.
|
| [6] |
WANG S X, CHEN J, LI Y M, et al. The detection method of rice seedling tray hole seeding quantity based on improved YOLOv5s[C]// 2023 5th International Conference on Robotics, Intelligent Control and Artificial Intelligence (RICAI). Piscataway, New Jersey, USA: IEEE, 2023: 1165-1169.
|
| [7] |
YAN Z Y, ZHAO Y M, LUO W S, et al. Machine vision-based tomato plug tray missed seeding detection and empty cell replanting[J]. Computers and Electronics in Agriculture, 2023, 208: 107800.
|
| [8] |
LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: Common objects in context[M]// Computer Vision-ECCV 2014. Cham: Springer International Publishing, 2014: 740-755.
|
| [9] |
GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]// 2014 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, New Jersey, USA: IEEE, 2014: 580-587.
|
| [10] |
LONG J, SHELHAMER E, DARRELL T. Fully convolutional networks for semantic segmentation[C]// 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway, New Jersey, USA: IEEE, 2015: 3431-3440.
|
| [11] |
HE K M, GKIOXARI G, DOLLAR P, et al. Mask R-CNN[C]// 2017 IEEE International Conference on Computer Vision (ICCV). Piscataway, New Jersey, USA: IEEE, 2017: 2980-2988.
|
| [12] |
REN S Q, HE K M, GIRSHICK R, et al. Faster R-CNN: Towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137-1149.
|
| [13] |
WOLF T, DEBUT L, SANH V, et al. Transformers: State-of-the-art natural language processing[C]// Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. Stroudsburg, PA, USA: ACL, 2020: 38-45.
|
| [14] |
CHENG B W, MISRA I, SCHWING A G, et al. Masked-attention mask transformer for universal image segmentation[C]// 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway, New Jersey, USA: IEEE, 2022: 1280-1289.
|
| [15] |
CHENG B, SCHWING A, KIRILLOV A. Per-pixel classification is not all you need for semantic segmentation[C/OL]// 35th Conference on Neural Information Processing Systems. 2021.[2025-07-06].
|
| [16] |
RADFORD A, KIM J W, HALLACY C, et al. Learning transferable visual models from natural language supervision[C]// International Conference on Machine Learning. Proceedings of Machine Learning Research. New York, USA: PMLR, 2021: 8748-8763..
|
| [17] |
TODA Y, OKURA F, ITO J, et al. Training instance segmentation neural network with synthetic datasets for crop seed phenotyping[J]. Communications Biology, 2020, 3(1): 173.
|
| [18] |
YE S, LIU W H, ZENG S, et al. SY-net: A rice seed instance segmentation method based on a six-layer feature fusion network and a parallel prediction head structure[J]. Sensors, 2023, 23(13): 6194.
|
| [19] |
GAO Q, LI H, MENG T Y, et al. A rapid construction method for high-throughput wheat grain instance segmentation dataset using high-resolution images[J]. Agronomy, 2024, 14(5): 1032.
|
| [20] |
TANG S X, XIA Z L, GU J N, et al. High-precision apple recognition and localization method based on RGB-D and improved SOLOv2 instance segmentation[J]. Frontiers in Sustainable Food Systems, 2024, 8: 1403872.
|
| [21] |
MA J, ZHAO Y K, FAN W P, et al. An improved YOLOv8 model for Lotus seedpod instance segmentation in the Lotus pond environment[J]. Agronomy, 2024, 14(6): 1325.
|
| [22] |
PENG Y, WANG A C, LIU J Z, et al. A comparative study of semantic segmentation models for identification of grape with different varieties[J]. Agriculture, 2021, 11(10): 997.
|
| [23] |
XING H, WAN Y K, ZHONG P, et al. Design and experimental analysis of real-time detection system for the seeding accuracy of rice pneumatic seed metering device based on the improved YOLOv5n[J]. Computers and Electronics in Agriculture, 2024, 227: 109614.
|
| [24] |
WU Z P, CHEN J, MA Z, et al. Development of a lightweight online detection system for impurity content and broken rate in rice for combine harvesters[J]. Computers and Electronics in Agriculture, 2024, 218: 108689.
|
| [25] |
MAO J, MA X, BI Y, et al. TJDR: A high-quality diabetic retinopathy pixel-level annotation dataset[EB/OL]. arXiv:2312.15389, 2023.
|
| [26] |
XIONG Y Y, VARADARAJAN B, WU L M, et al. EfficientSAM: Leveraged masked image pretraining for efficient segment anything[C]// 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway, New Jersey, USA: IEEE, 2024: 16111-16121.
|
| [27] |
WU J Z, LI X T, DING H H, et al. Betrayed by captions: Joint caption grounding and generation for open vocabulary instance segmentation[C]// 2023 IEEE/CVF International Conference on Computer Vision (ICCV). Piscataway, New Jersey, USA: IEEE, 2023: 21881-21891.
|
| [28] |
MILLETARI F, NAVAB N, AHMADI S A. V-net: Fully convolutional neural networks for volumetric medical image segmentation[C]// 2016 Fourth International Conference on 3D Vision (3DV). Piscataway, New Jersey, USA: IEEE, 2016: 565-571.
|
| [29] |
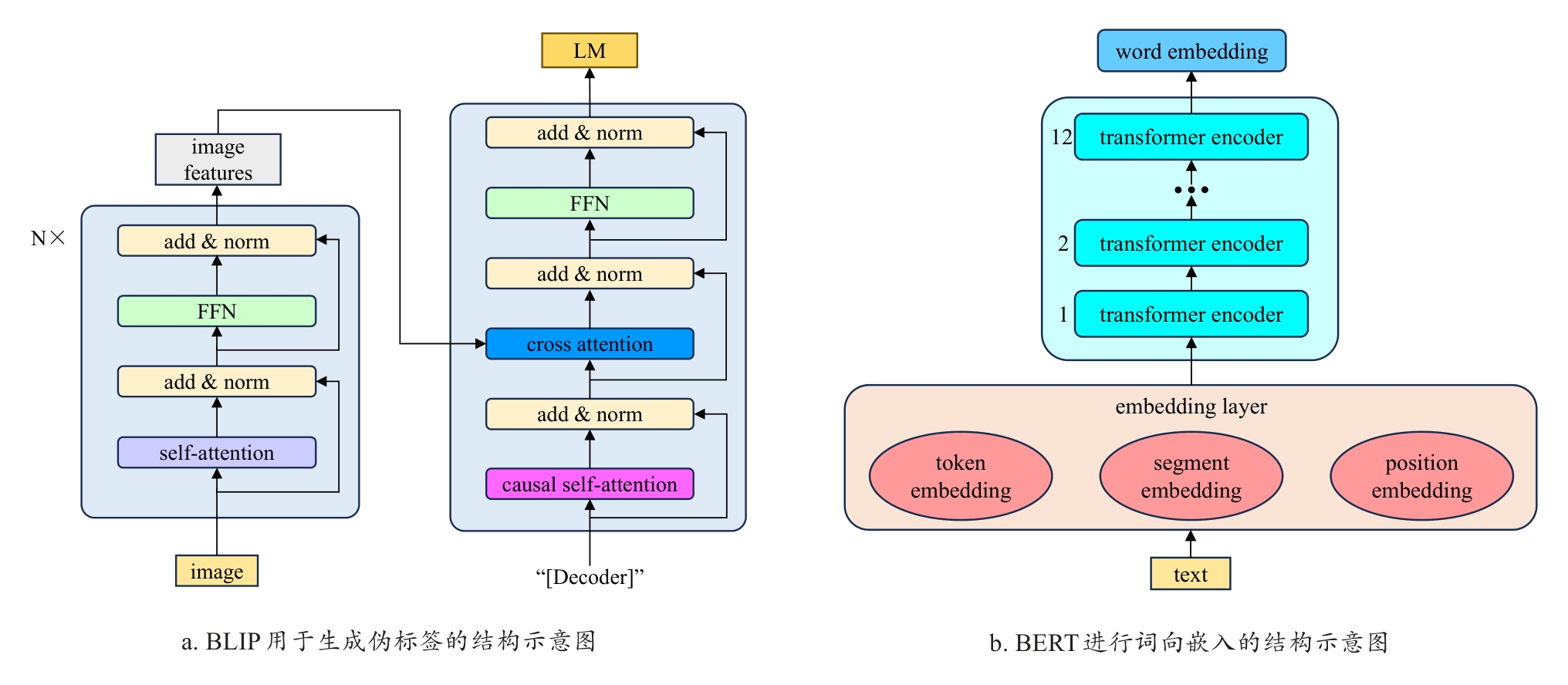
LI J, LI D, XIONG C, et al. BLIP: Bootstrapping language-image pre-training for unified vision-language understanding and generation[C]// International Conference on Machine Learning. Proceedings of Machine Learning Research. New York, USA: PMLR, 2022: 12888-12900..
|
| [30] |
KOROTEEV M V. BERT: A review of applications in natural language processing and understanding[EB/OL]. arXiv:2103.11943, 2021.
|
 ), 陈进1, 李耀明2, 陈宇航1, 严昊1
), 陈进1, 李耀明2, 陈宇航1, 严昊1