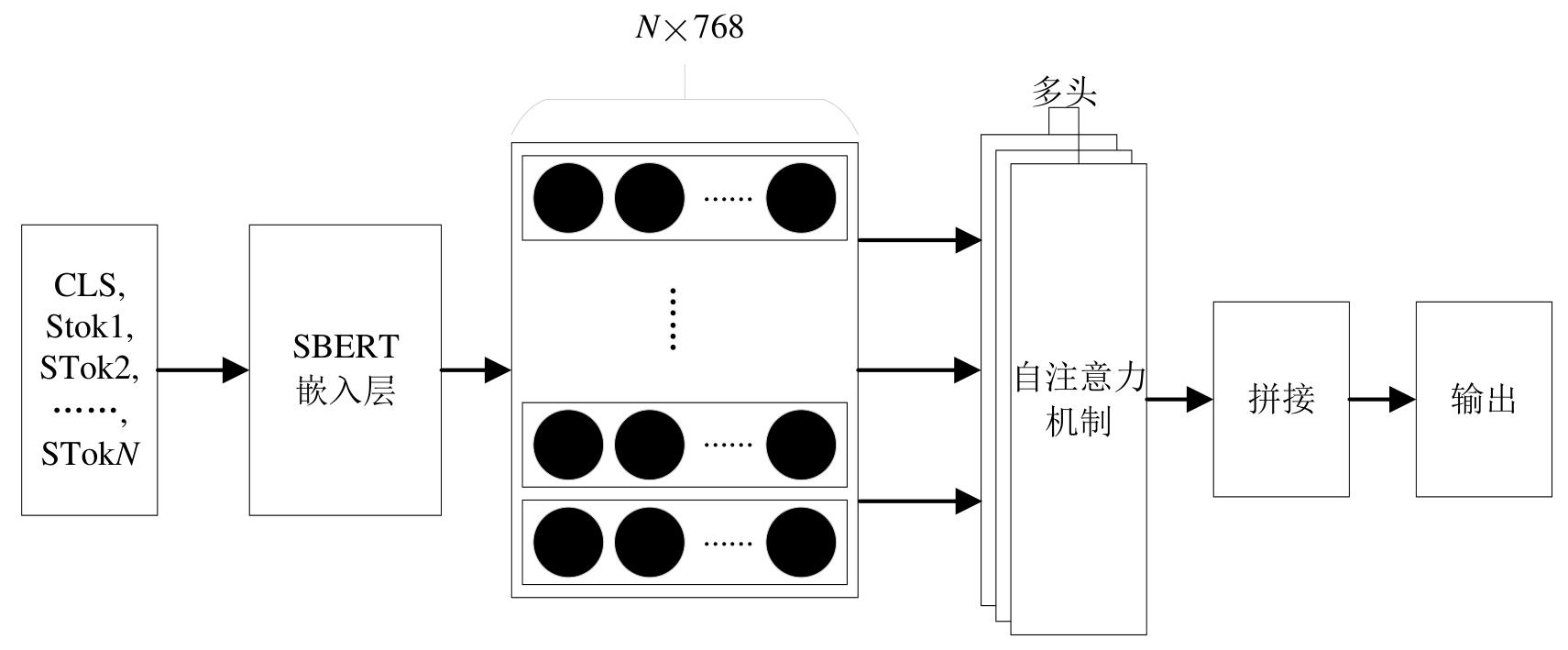
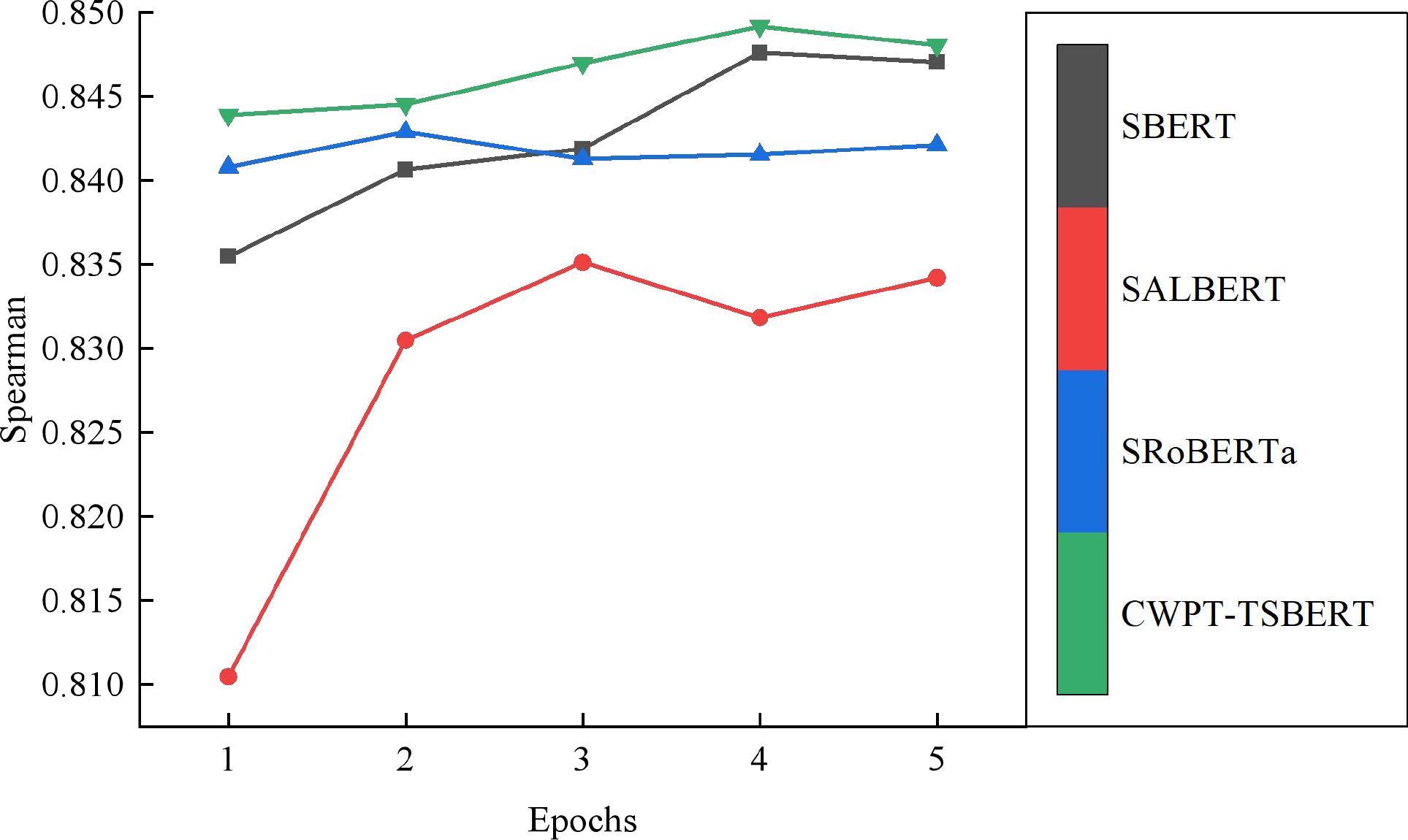
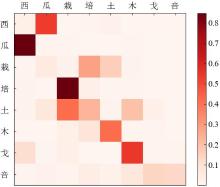
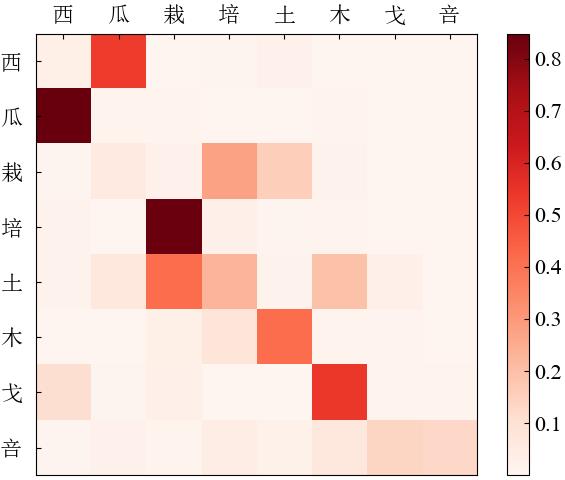
| 1 |
中国农技推广信息平台[DB/OL]. [2023-10-20].
|
| 2 |
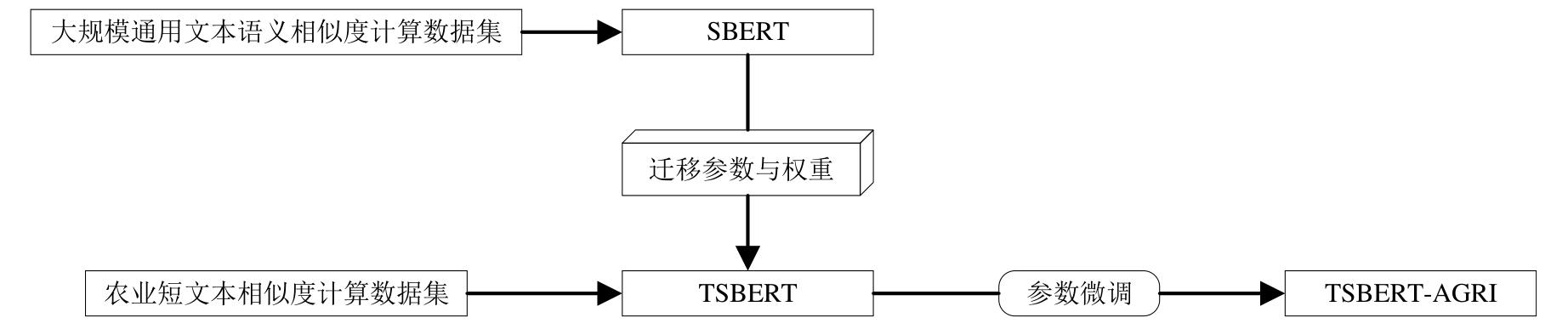
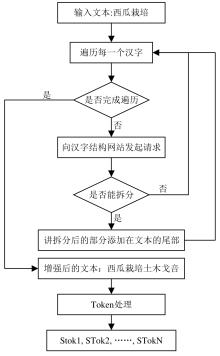
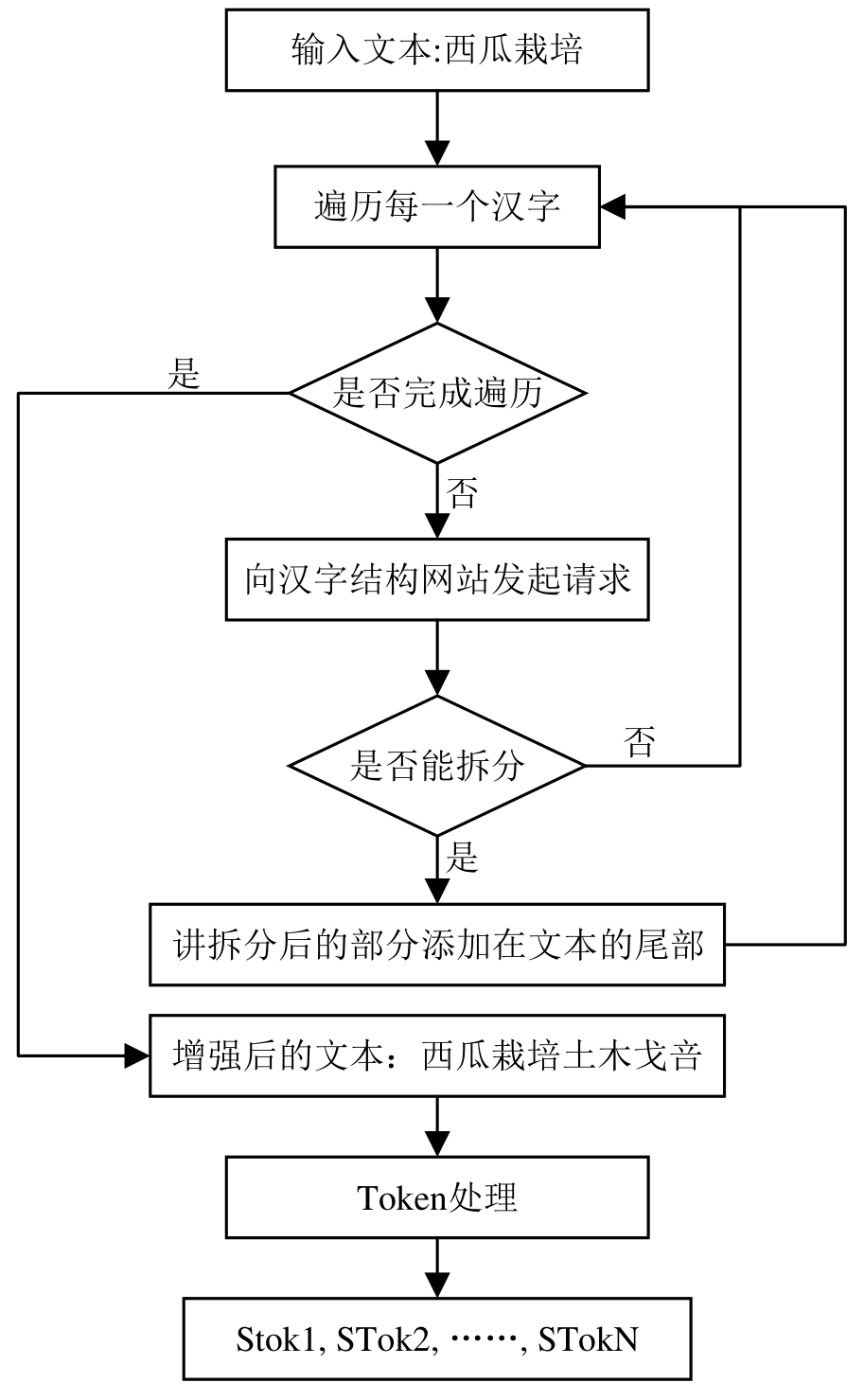
饶海笛. 基于语义的作物病虫害多模态知识问答方法研究[D]. 合肥: 安徽农业大学, 2023.
|
|
RAO H D. Semantic-based multimodal knowledge question answer method for crop pests and diseases[D]. Hefei: Anhui Agricultural University, 2023.
|
| 3 |
徐传丽, 周世杰, 吴春江. 深度学习中文本相似度计算研究综述[J]. 计算机应用与软件, 2024, 41(11): 1-14.
|
|
XU C L, ZHOU S J, WU C J. Review of textual similarity calculation in deep learning[J]. Computer applications and software, 2024, 41(11): 1-14.
|
| 4 |
WANG Z G, HAMZA W, FLORIAN R, et al. Bilateral multi-perspective matching for natural language sentences[C]// Proceedings of the 26th International Joint Conference on Artificial Intelligence. New York, USA: ACM, 2017: 4144-4150.
|
| 5 |
CHEN Q, ZHU X D, LING Z H, et al. Enhanced LSTM for natural language inference[EB/OL]. arXiv:1609.06038, 2016.
|
| 6 |
WANG B N, LIU K, ZHAO J. Inner attention based recurrent neural networks for answer selection[C]// Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics. San Diego, USA: ACL, 2016: 1288-1297.
|
| 7 |
PANG L, LAN Y Y, GUO J F, et al. Text matching as image recognition[C]// Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence. New York, USA: ACM, 2016: 2793-2799.
|
| 8 |
庞亮, 兰艳艳, 徐君, 等. 深度文本匹配综述[J]. 计算机学报, 2017, 40(4): 985-1003.
|
|
PANG L, LAN Y Y, XU J, et al. A survey on deep text matching[J]. Chinese journal of computers, 2017, 40(4): 985-1003.
|
| 9 |
DEVLIN J, CHANG M W, LEE K, et al. BERT: Pre-training of deep bidirectional transformers for language understanding[EB/OL]. arXiv:1810.04805, 2018.
|
| 10 |
代翔, 孙海春, 牛硕, 等. 融合互注意力机制与BERT的中文问答匹配技术研究[J]. 信息网络安全, 2021, 21(12): 102-108.
|
|
DAI X, SUN H C, NIU S, et al. Research on Chinese question answering matching based on mutual attention mechanism and bert[J]. Netinfo security, 2021, 21(12): 102-108.
|
| 11 |
马新宇, 范意兴, 郭嘉丰, 等. 关于短文本匹配的泛化性和迁移性的研究分析[J]. 计算机研究与发展, 2022, 59(1): 118-126.
|
|
MA X Y, FAN Y X, GUO J F, et al. An empirical investigation of generalization and transfer in short text matching[J]. Journal of computer research and development, 2022, 59(1): 118-126.
|
| 12 |
REIMERS N, GUREVYCH I. Sentence-BERT: Sentence embeddings using Siamese BERT-networks[EB/OL]. arXiv: 1908. 10084, 2019.
|
| 13 |
RYU M H. RE ALBERT: A lite BERT for self-supervised learning of language representations[EB/OL]. arXiv:1909.11942, 2020.
|
| 14 |
LI J Y, ZHANG X J, ZHOU X B. ALBERT-based self-ensemble model with semisupervised learning and data augmentation for clinical semantic textual similarity calculation: Algorithm validation study[J]. JMIR medical informatics, 2021, 9(1): ID e23086.
|
| 15 |
BAI J G, WANG Y J, CHEN Y R, et al. Syntax-BERT: Improving pre-trained transformers with syntax trees[EB/OL]. arXiv:2103.04350, 2021.
|
| 16 |
YANG J L. An empirical study for the GPT-based LLM in paper similarity measurement[C]// 2024 5th International Conference on Electronic Communication and Artificial Intelligence (ICECAI). Piscataway, New Jersey, USA: IEEE, 2024: 814-818.
|
| 17 |
XU S C, WU Z H, ZHAO H Q, et al. Reasoning before comparison: LLM-enhanced semantic similarity metrics for domain specialized text analysis[EB/OL]. arXiv: 2402.11398, 2024.
|
| 18 |
王郝日钦, 王晓敏, 缪祎晟, 等. 基于BERT-Attention-DenseBiGRU的农业问答社区问句相似度匹配[J]. 农业机械学报, 2022, 53(1): 244-252.
|
|
WANG H, WANG X M, MIAO Y S, et al. Densely connected BiGRU neural network based on BERT and attention mechanism for Chinese agriculture-related question similarity matching[J]. Transactions of the Chinese society for agricultural machinery, 2022, 53(1): 244-252.
|
| 19 |
ZHOU H, GUO X, LIU C, et al. Question similarity measurement of Chinese crop diseases and insect pests based on mixed information extraction[J]. KSII transactions on Internet and information systems, 2021, 15(11): 3991-4010.
|
| 20 |
王奥, 吴华瑞, 朱华吉. 基于特征增强的多方位农业问句语义匹配[J]. 西南大学学报(自然科学版), 2023, 45(6): 201-210.
|
|
WANG A, WU H R, ZHU H J. Multi-level semantic matching of agricultural questions based on feature enhancement[J]. Journal of southwest university (natural science edition), 2023, 45(6): 201-210.
|
| 21 |
刘志超, 王晓敏, 吴华瑞, 等. 基于BiLSTM-CNN的水稻问句相似度匹配方法研究[J]. 中国农机化学报, 2022, 43(12): 125-132.
|
|
LIU Z C, WANG X M, WU H R, et al. Research on rice question and sentence similarity matching method based on BiLSTM-CNN[J]. Journal of Chinese agricultural mechanization, 2022, 43(12): 125-132.
|
| 22 |
张莉, 杨明辉, 孙嘉成. 基于注意力机制和迁移学习的小样本茶叶病害识别[J]. 中国农机化学报, 2024, 45(10): 262-268.
|
|
ZHANG L, YANG M H, SUN J C. Identification method of small sample tea leaf diseases based on attention mechanism and transfer learning[J]. Journal of Chinese agricultural mechanization, 2024, 45(10): 262-268.
|
| 23 |
张国忠, 吕紫薇, 刘浩蓬, 等. 基于改进DenseNet和迁移学习的荷叶病虫害识别模型[J]. 农业工程学报, 2023, 39(8): 188-196.
|
|
ZHANG G Z, LYU Z W, LIU H P, et al. Model for identifying Lotus leaf pests and diseases using improved DenseNet and transfer learning[J]. Transactions of the Chinese society of agricultural engineering, 2023, 39(8): 188-196.
|
| 24 |
SHAFIK W, TUFAIL A, DE SILVA LIYANAGE C, et al. Using transfer learning-based plant disease classification and detection for sustainable agriculture[J]. BMC plant biology, 2024, 24(1): ID 136.
|
| 25 |
LIU Z H, LI J H, ASHRAF M, et al. Remote sensing-enhanced transfer learning approach for agricultural damage and change detection: A deep learning perspective[J]. Big data research, 2024, 36: ID 100449.
|
| 26 |
BRITO D F, CARDOSO J L, DOS REIS J C, et al. Exploring supervised techniques for automated recognition of intention classes from Portuguese free texts on agriculture[J]. Revista de informática Teórica e aplicada, 2022, 29(2): 95-120.
|
| 27 |
LIU X, CHEN Q, DENG C, et al. Lcqmc: A large-scale chinese question matching corpus[C]// Proceedings of the 27th international conference on computational linguistics. San Diego, USA: ACL, 2018: 1952-1962.
|
| 28 |
MUELLER J, THYAGARAJAN A, MUELLER J, et al. Siamese recurrent architectures for learning sentence similarity[C]// Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence. New York, USA: ACM, 2016: 2786-2792.
|
| 29 |
NECULOIU P, VERSTEEGH M, ROTARU M. Learning text similarity with Siamese recurrent networks[C]// Proceedings of the 1st Workshop on Representation Learning for NLP. San Diego, USA: ACL, 2016: 148-157.
|
| 30 |
XIANG H, GU J G. Research on question answering system based on Bi-LSTM and self-attention mechanism[C]// 2020 IEEE 7th International Conference on Industrial Engineering and Applications (ICIEA). Piscataway, New Jersey, USA: IEEE, 2020: 726-730.
|
| 31 |
SHI H X, WANG C, SAKAI T. A Siamese CNN architecture for learning Chinese sentence similarity[C]// Proceedings of the 1st Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 10th International Joint Conference on Natural Language. San Diego, USA: ACL, 2020: 24-29.
|
| 32 |
ALSHUBAILY I. TextCNN with Attention forText Classification[EB/OL]. arXiv: 2108. 01921, 2021.
|
| 33 |
LIU Y H, OTT M, GOYAL N, et al. RoBERTa: A robustly optimized BERT pretraining approach[EB/OL]. arXiv:1907.11692, 2019.
|
 )
)