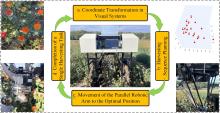
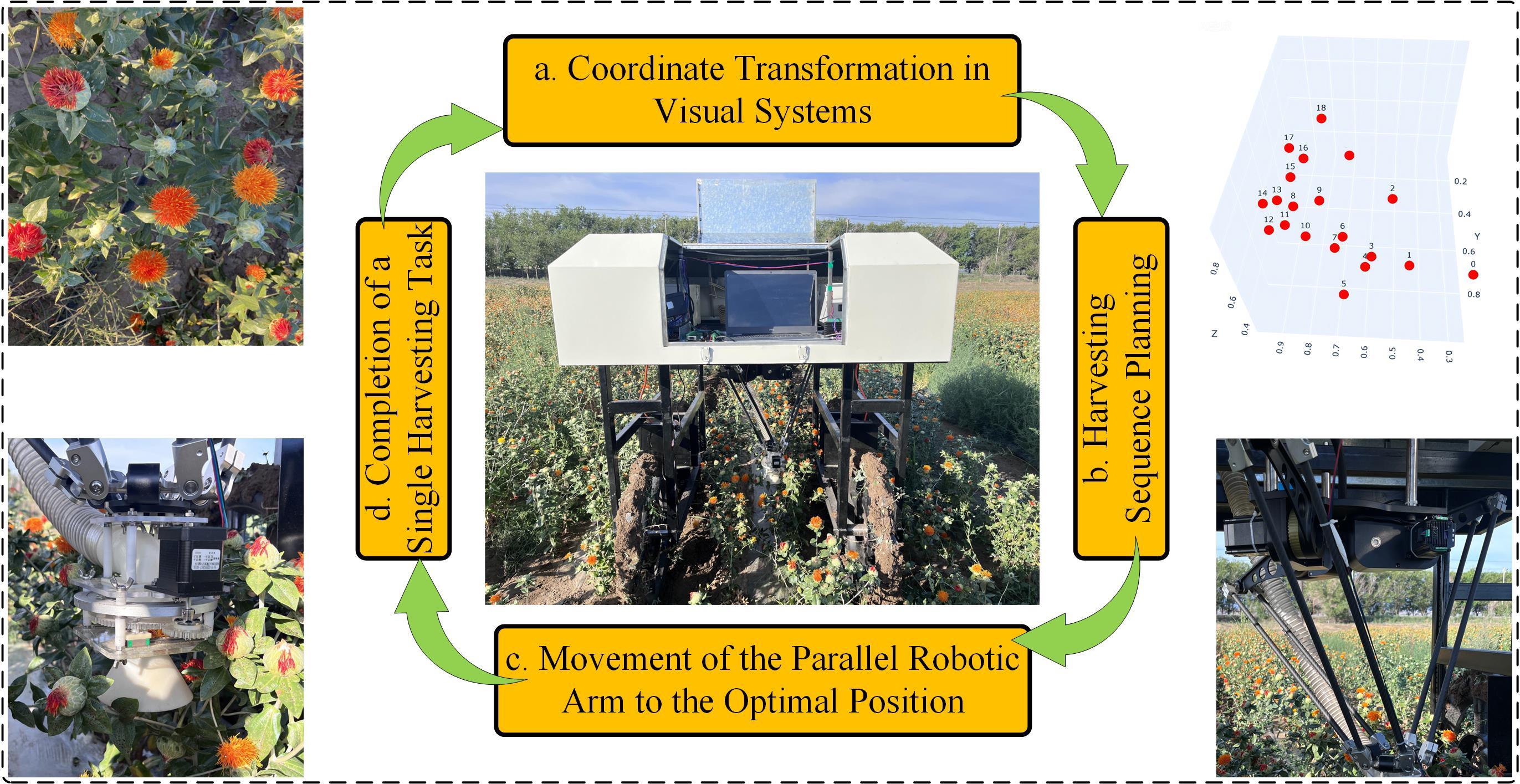
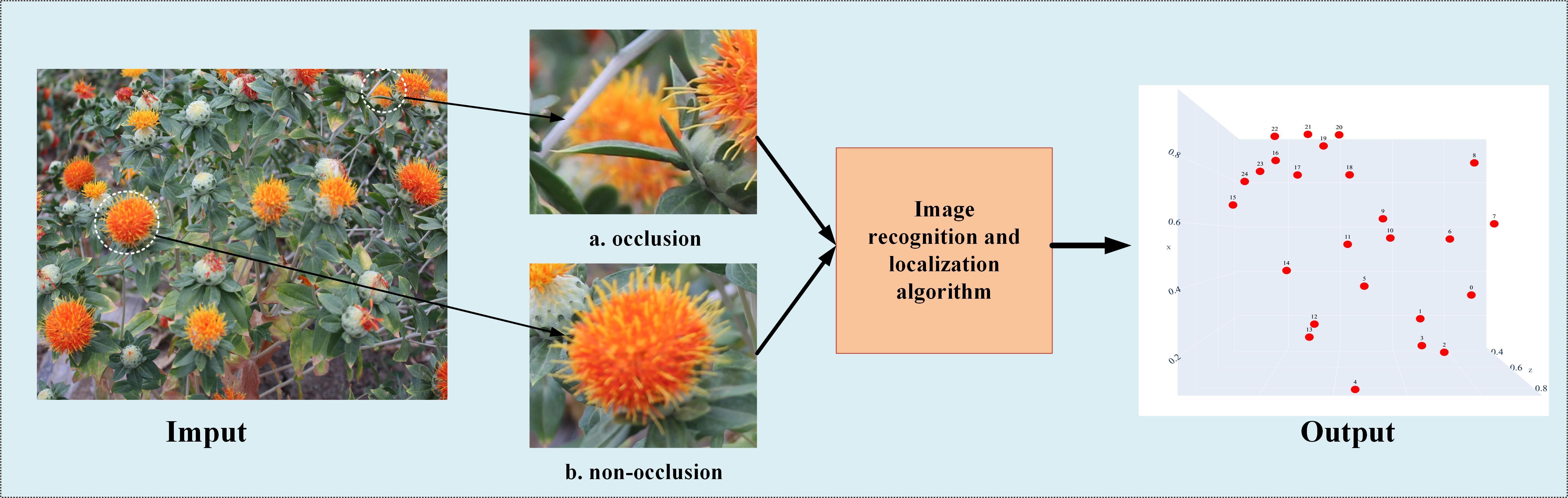
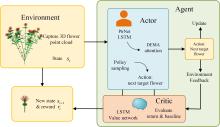
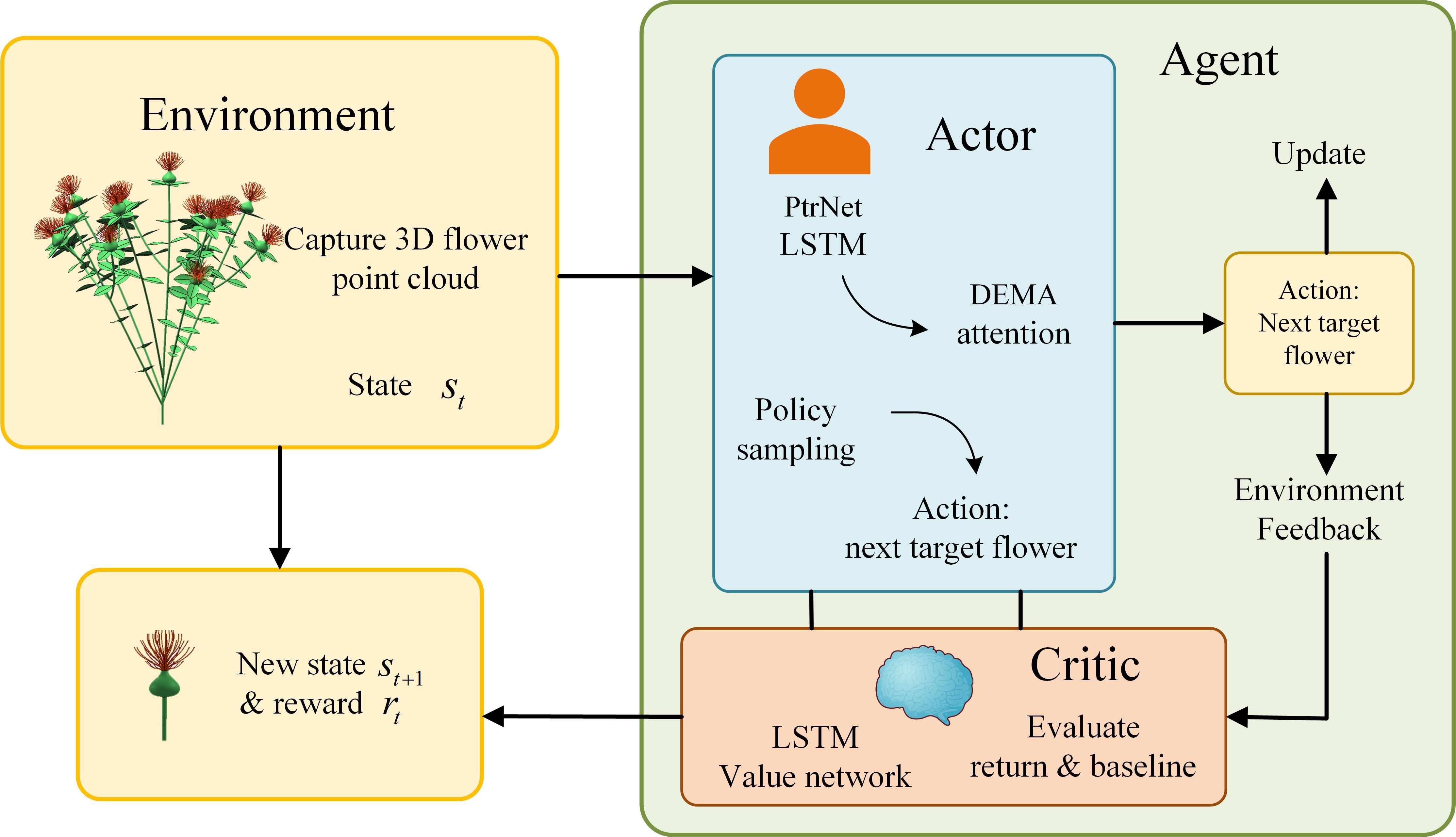
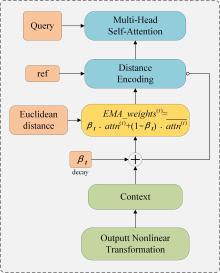
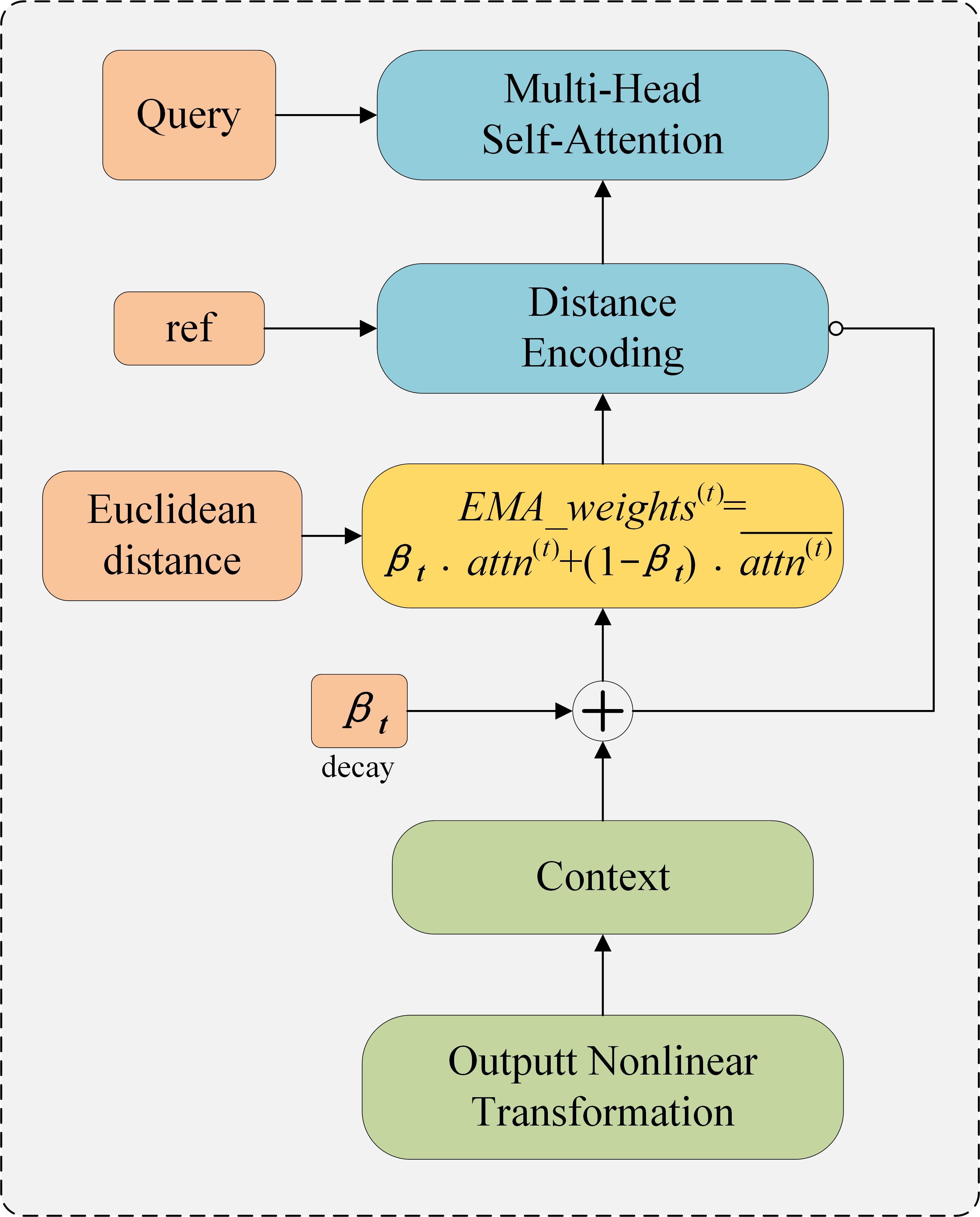
| [1] |
LU J X, ZHANG C X, HU Y, et al. Application of multiple chemical and biological approaches for quality assessment of Carthamus tinctorius L. (safflower) by determining both the primary and secondary metabolites[J]. Phytomedicine, 2019, 58: 152826.
|
| [2] |
WANG L, CHEN Z, HAN B, et al. Comprehensive analysis of volatile compounds in cold-pressed safflower seed oil from Xinjiang, China[J]. Food Science & Nutrition, 2020, 8(2): 903-914.
|
| [3] |
MA B J, XIA H, GE Y, et al. A method for identifying picking points in safflower point clouds based on an improved PointNet++ network[J]. Agronomy, 2025, 15(5): 1125.
|
| [4] |
WANG X R, ZHOU J P, XU Y, et al. Location of safflower filaments picking points in complex environment based on improved YOLOv5 algorithm[J]. Computers and Electronics in Agriculture, 2024, 227: 109463.
|
| [5] |
ZHANG Z G, WANG Y Z, XU P, et al. WED-YOLO: A detection model for safflower under complex unstructured environment[J]. Agriculture, 2025, 15(2): 205.
|
| [6] |
LI Y J, FENG Q C, LIU C, et al. MTA-YOLACT: Multitask-aware network on fruit bunch identification for cherry tomato robotic harvesting[J]. European Journal of Agronomy, 2023, 146: 126812.
|
| [7] |
JIANG Y W, CHEN J, WANG Z W, et al. Research progress and trend analysis of picking technology for Korla fragrant pear[J]. Horticulturae, 2025, 11(1): 90.
|
| [8] |
ZHAO C J, FAN B B, LI J, et al. Agricultural robots: Technology progress, challenges and trends[J]. Smart Agriculture, 2023, 5(4): 1-15.
|
| [9] |
DONG Z, ZHANG X H, YANG W J, et al. Ant colony optimization-based method for energy-efficient cutting trajectory planning in axial robotic roadheader[J]. Applied Soft Computing, 2024, 163: 111965.
|
| [10] |
CHEN D W, IMDAHL C, LAI D, et al. The Dynamic Traveling Salesman Problem with Time-Dependent and Stochastic travel times: A deep reinforcement learning approach[J]. Transportation Research Part C: Emerging Technologies, 2025, 172: 105022.
|
| [11] |
GUO Z W, FU H, WU J H, et al. Dynamic task planning for multi-arm apple-harvesting robots using LSTM-PPO reinforcement learning algorithm[J]. Agriculture, 2025, 15(6): 588.
|
| [12] |
LIU C J, ZHONG Y L, WU R L, et al. Deep reinforcement learning based 3D-trajectory design and task offloading in UAV-enabled MEC system[J]. IEEE Transactions on Vehicular Technology, 2025, 74(2): 3185-3195.
|
| [13] |
JATI G K, KUWANTO G, HASHMI T, et al. Discrete Komodo algorithm for traveling salesman problem[J]. Applied Soft Computing, 2023, 139: 110219.
|
| [14] |
SOITINAHO R, VÄYRYNEN V, OKSANEN T. Heuristic cooperative coverage path planning for multiple autonomous agricultural field machines performing sequentially dependent tasks of different working widths and turn characteristics[J]. Biosystems Engineering, 2024, 242: 16-28.
|
| [15] |
UTAMIMA A, REINERS T. Navigating route planning for multiple vehicles in multifield agriculture with a fast hybrid algorithm[J]. Computers and Electronics in Agriculture, 2023, 212: 108021.
|
| [16] |
GAO R L, ZHOU Q J, CAO S X, et al. Apple-picking robot picking path planning algorithm based on improved PSO[J]. Electronics, 2023, 12(8): 1832.
|
| [17] |
FANG S P, RU Y, HU C M, et al. Planning of takeoff/landing site location, dispatch route, and spraying route for a pesticide application helicopter[J]. European Journal of Agronomy, 2023, 146: 126814.
|
| [18] |
LI X M, GENG L B, LIU K Z, et al. Model-based offline reinforcement learning for AUV path-following under unknown ocean currents with limited data[J]. Drones, 2025, 9(3): 201.
|
| [19] |
SHEN J, CHEN M C, ZHANG Z C, et al. Model-based offline policy optimization with distribution correcting regularization[C]// Machine Learning and Knowledge Discovery in Databases. Research Track. Cham, Germany: Springer, 2021: 174-189.
|
| [20] |
SHARMA G, SINGH A, JAIN S. DeepEvap: Deep reinforcement learning based ensemble approach for estimating reference evapotranspiration[J]. Applied Soft Computing, 2022, 125: 109113.
|
| [21] |
ZHANG Q, FANG X W, GAO X D, et al. Optimising maize threshing process with temporal proximity soft actor-critic deep reinforcement learning algorithm[J]. Biosystems Engineering, 2024, 248: 229-239.
|
| [22] |
YANG J C, NI J F, LI Y, et al. The intelligent path planning system of agricultural robot via reinforcement learning[J]. Sensors, 2022, 22(12): 4316.
|
| [23] |
LIN G C, ZHU L X, LI J H, et al. Collision-free path planning for a guava-harvesting robot based on recurrent deep reinforcement learning[J]. Computers and Electronics in Agriculture, 2021, 188: 106350.
|
| [24] |
SANTIYUDA G, WARDOYO R, PULUNGAN R. Solving biobjective traveling thief problems with multiobjective reinforcement learning[J]. Applied Soft Computing, 2024, 161: 111751.
|
| [25] |
BELLO I, PHAM H, LE Q V, et al. Neural combinatorial optimization with reinforcement learning[EB/OL]. arXiv: 1611.09940, 2016.
|
| [26] |
GU S S, YANG Y. A deep learning algorithm for the max-cut problem based on pointer network structure with supervised learning and reinforcement learning strategies[J]. Mathematics, 2020, 8(2): 298.
|
| [27] |
LIN G C, XIONG J T, ZHAO R M, et al. Efficient detection and picking sequence planning of tea buds in a high-density canopy[J]. Computers and Electronics in Agriculture, 2023, 213: 108213.
|
| [28] |
WANG X R, XU Y, ZHOU J P, et al. Safflower picking recognition in complex environments based on an improved YOLOv7[J]. Transactions of the Chinese Society of Agricultural Engineering, 2023, 39(6): 169-176.
|
| [29] |
BELHADI A, DJENOURI Y, BELBACHIR A N, et al. Shapley visual transformers for image-to-text generation[J]. Applied Soft Computing, 2024, 166: 112205.
|
| [30] |
SUTTON R S, MCALLESTER D, SINGH S, et al. Policy gradient methods for reinforcement learning with function approximation[C]// Proceedings of the 13th International Conference on Neural Information Processing Systems. New York, USA: ACM, 1999: 1057-1063.
|
| [31] |
BRAUWERS G, FRASINCAR F. A general survey on attention mechanisms in deep learning[J]. IEEE Transactions on Knowledge and Data Engineering, 2023, 35(4): 3279-3298.
|
| [32] |
LIU Y, ZHANG C, HANG B, et al. An audio attention computational model based on information entropy of two channels and exponential moving average[J]. Human-Centric Computing and Information Sciences, 2019, 9(1): 7.
|
| [33] |
HE Y, XIAO L G. Structured pruning for deep convolutional neural networks: A survey[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024, 46(5): 2900-2919.
|
| [34] |
WANG Z, LI C C, WANG X Y. Convolutional neural network pruning with structural redundancy reduction[C]// 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway, New Jersey, USA: IEEE, 2021: 14908-14917.
|
| [35] |
JIANG P C, XUE Y, NERI F. Convolutional neural network pruning based on multi-objective feature map selection for image classification[J]. Applied Soft Computing, 2023, 139: 110229.
|
| [36] |
CHEN J L, ZHAO P, CAO X L, et al. Lightweight YOLOv8s-based strawberry plug seedling grading detection and localization via channel pruning[J]. Smart Agriculture, 2024, 6(6): 132-143.
|
| [37] |
ZHU K H, HU F Y, DING Y B, et al. A comprehensive review of network pruning based on pruning granularity and pruning time perspectives[J]. Neurocomputing, 2025, 626: 129382.
|
 ), 刘子贺1, 段孟渝1, 金正阳1
), 刘子贺1, 段孟渝1, 金正阳1