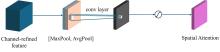
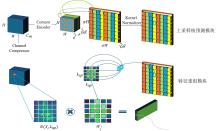
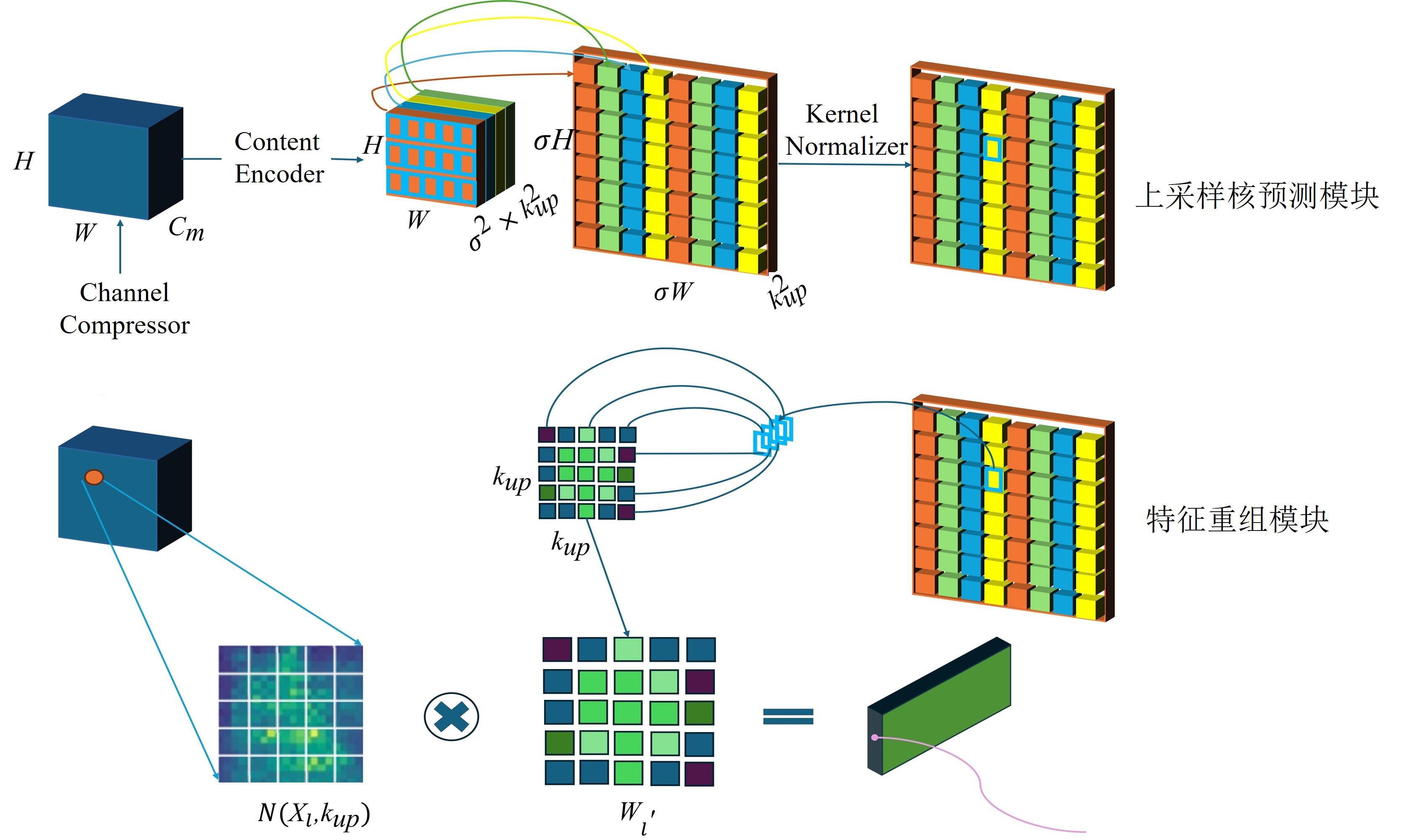
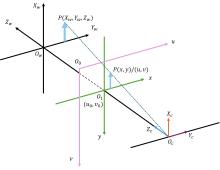
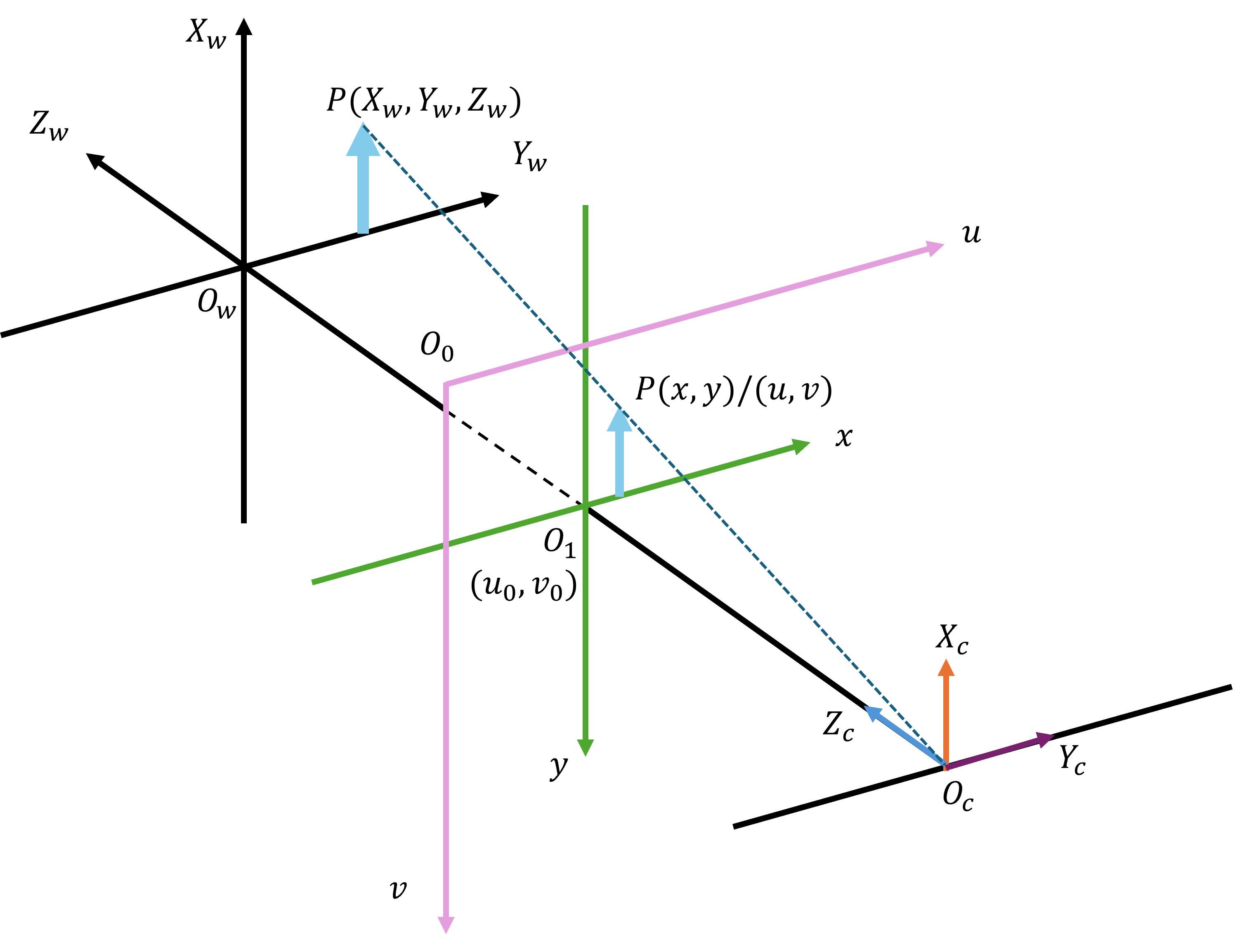
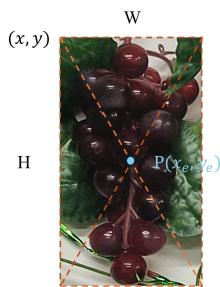
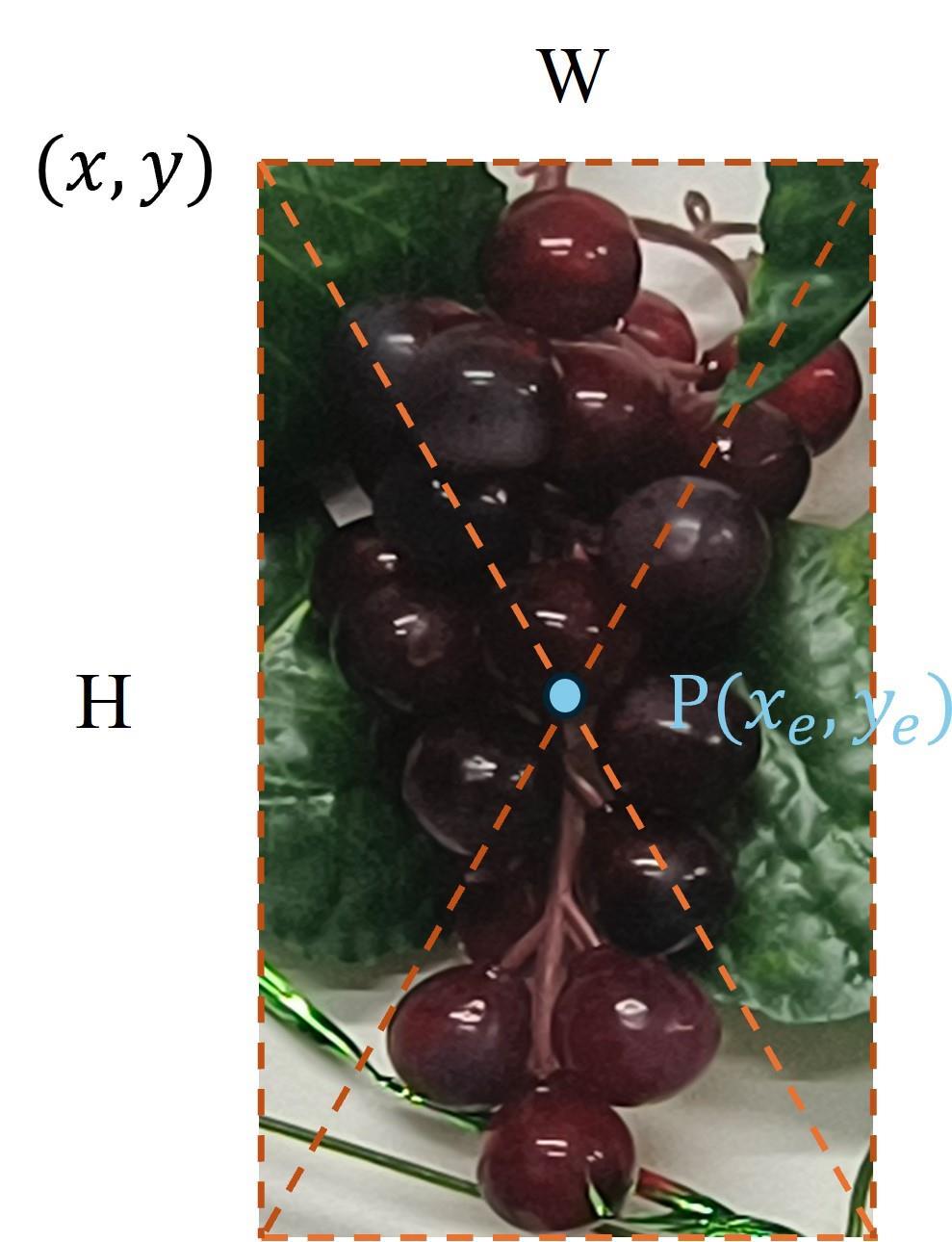
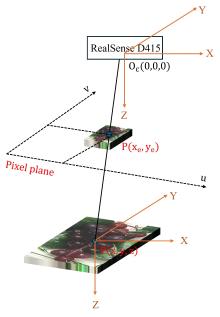
| 1 |
赵梦瑶, 赵君彦, 张泽, 等. 我国鲜食葡萄价格波动特征及影响因素研究[J]. 北方园艺, 2024(18): 136-144.
|
|
ZHAO M Y, ZHAO J Y, ZHANG Z, et al. Study on price fluctuation characteristics and influencing factors of table grape in China[J]. Northern horticulture, 2024(18): 136-144.
|
| 2 |
言九. 2023年全球与中国葡萄行业产量、消费量、进出口数量及区域分布情况[DS/OL]. (2023-07-20) [2024-07-02].
|
| 3 |
OTANI T, ITOH A, MIZUKAMI H, et al. Agricultural robot under solar panels for sowing, pruning, and harvesting in a synecoculture environment[J]. Agriculture, 2022, 13(1): ID 18.
|
| 4 |
VROCHIDOU E, TSAKALIDOU V N, KALATHAS I, et al. An overview of end effectors in agricultural robotic harvesting systems[J]. Agriculture, 2022, 12(8): ID 1240.
|
| 5 |
FAN P, LANG G D, GUO P J, et al. Multi-feature patch-based segmentation technique in the gray-centered RGB color space for improved apple target recognition[J]. Agriculture, 2021, 11(3): ID 273.
|
| 6 |
KONDO N. Study on grape harvesting robot[J]. IFAC proceedings volumes, 1991, 24(11): 243-246.
|
| 7 |
CHAIVIVATRAKUL S, DAILEY M N. Texture-based fruit detection[J]. Precision agriculture, 2014, 15(6): 662-683.
|
| 8 |
李欣, 齐家敏, 程昊, 等. 基于机器视觉的谷糙分离检测方法[J]. 食品与机械, 2024, 40(6): 97-103.
|
|
LI X, QI J M, CHENG H, et al. Grain and chaff separation detection method based on machine vision[J]. Food & machinery, 2024, 40(6): 97-103.
|
| 9 |
LIU S, WHITTY M. Automatic grape bunch detection in vineyards with an SVM classifier[J]. Journal of applied logic, 2015, 13(4): 643-653.
|
| 10 |
李欣, 王玉德. 基于颜色模型和阈值分割的有遮挡的柑橘果实识别算法[J]. 计算技术与自动化, 2022, 41(2): 136-140.
|
|
LI X, WANG Y D. Occluded citrus fruit recognition algorithm based on color model and threshold segmentation[J]. Computing technology and automation, 2022, 41(2): 136-140.
|
| 11 |
DARWIN B, DHARMARAJ P, PRINCE S, et al. Recognition of bloom/yield in crop images using deep learning models for smart agriculture: A review[J]. Agronomy, 2021, 11(4): ID 646.
|
| 12 |
CECOTTI H, RIVERA A, FARHADLOO M, et al. Grape detection with convolutional neural networks[J]. Expert systems with applications, 2020, 159: ID 113588.
|
| 13 |
YIN W, WEN H J, NING Z T, et al. Fruit detection and pose estimation for grape cluster-harvesting robot using binocular imagery based on deep neural networks[J]. Frontiers in robotics and AI, 2021, 8: ID 626989.
|
| 14 |
GIRSHICK R. Fast R-CNN[C]// 2015 IEEE International Conference on Computer Vision (ICCV). Piscataway, New Jersey, USA: IEEE, 2015: 1440-1448.
|
| 15 |
REN S Q, HE K M, GIRSHICK R, et al. Faster R-CNN: Towards real-time object detection with region proposal networks[J]. IEEE transactions on pattern analysis and machine intelligence, 2017, 39(6): 1137-1149.
|
| 16 |
CAI Z W, VASCONCELOS N. Cascade R-CNN: Delving into high quality object detection[C]// 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, New Jersey, USA: IEEE, 2018: 6154-6162.
|
| 17 |
PANG J M, CHEN K, SHI J P, et al. Libra R-CNN: Towards balanced learning for object detection[C]// 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway, New Jersey, USA: IEEE, 2019: 821-830.
|
| 18 |
朱旭, 马淏, 姬江涛, 等. 基于Faster R-CNN的蓝莓冠层果实检测识别分析[J]. 南方农业学报, 2020, 51(6): 1493-1501.
|
|
ZHU X, MA H, JI J T, et al. Detecting and identifying blueberry canopy fruits based on Faster R-CNN[J]. Journal of southern agriculture, 2020, 51(6): 1493-1501.
|
| 19 |
LIU W, ANGUELOV D, ERHAN D, et al. SSD: Single shot MultiBox detector[M]// Lecture Notes in Computer Science. Cham: Springer International Publishing, 2016: 21-37.
|
| 20 |
LIN T Y, GOYAL P, GIRSHICK R, et al. Focal loss for dense object detection[C]// 2017 IEEE International Conference on Computer Vision (ICCV). Piscataway, New Jersey, USA: IEEE, 2017: 2980-2988.
|
| 21 |
TAN M X, PANG R M, LE Q V. EfficientDet: Scalable and efficient object detection[C]// 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway, New Jersey, USA: IEEE, 2020: 10781-10790.
|
| 22 |
REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: Unified, real-time object detection[C]// 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway, New Jersey, USA: IEEE, 2016: 779-788.
|
| 23 |
REDMON J, FARHADI A. YOLO9000: Better, faster, stronger[C]// 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway, New Jersey, USA: IEEE, 2017: 7263-7271.
|
| 24 |
REDMON J, FARHADI A. YOLOv3: An incremental improvement[EB/OL]. arXiv:1804.02767, 2018.
|
| 25 |
BOCHKOVSKIY A, WANG C Y, LIAO H Y M. YOLOv4: Optimal speed and accuracy of object detection[EB/OL]. arXiv: 2004.10934, 2020.
|
| 26 |
MOREIRA G, MAGALHÃES S A, PINHO T, et al. Benchmark of deep learning and a proposed HSV colour space models for the detection and classification of greenhouse tomato[J]. Agronomy, 2022, 12(2): ID 356.
|
| 27 |
SU S Z, CHEN R B, FANG X J, et al. A novel lightweight grape detection method[J]. Agriculture, 2022, 12(9): ID 1364.
|
| 28 |
陈青, 殷程凯, 郭自良, 等. 苹果采摘机器人关键技术研究现状与发展趋势[J]. 农业工程学报, 2023, 39(4): 1-15.
|
|
CHEN Q, YIN C K, GUO Z L, et al. Current status and future development of the key technologies for apple picking robots[J]. Transactions of the Chinese society of agricultural engineering, 2023, 39(4): 1-15.
|
| 29 |
TAFURO A, ADEWUMI A, PARSA S, et al. Strawberry picking point localization ripeness and weight estimation[C]// 2022 International Conference on Robotics and Automation (ICRA). Piscataway, New Jersey, USA: IEEE, 2022: 2295-2302.
|
| 30 |
DU W S, JIA Z H, SUI S S, et al. Table grape inflorescence detection and clamping point localisation based on channel pruned YOLOv7-TP[J]. Biosystems engineering, 2023, 235: 100-115.
|
| 31 |
宁政通, 罗陆锋, 廖嘉欣, 等. 基于深度学习的葡萄果梗识别与最优采摘定位[J]. 农业工程学报, 2021, 37(9): 222-229.
|
|
NING Z T, LUO L F, LIAO J X, et al. Recognition and the optimal picking point location of grape stems based on deep learning[J]. Transactions of the Chinese society of agricultural engineering, 2021, 37(9): 222-229.
|
| 32 |
WANG G, CHEN Y F, AN P, et al. UAV-YOLOv8: A small-object-detection model based on improved YOLOv8 for UAV aerial photography scenarios[J]. Sensors, 2023, 23(16): ID 7190.
|
| 33 |
TANG H Y, LIANG S, YAO D, et al. A visual defect detection for optics lens based on the YOLOv5-C3CA-SPPF network model[J]. Optics express, 2023, 31(2): 2628-2643.
|
| 34 |
WANG S B, CHEN R H, WU H Y, et al. YOLOH: You only look one hourglass for real-time object detection[J]. IEEE transactions on image processing, 2024, 33: 2104-2115.
|
| 35 |
CHEN S L, ZHAO J Q, ZHOU Y, et al. Info-FPN: An informative feature pyramid network for object detection in remote sensing images[J]. Expert systems with applications, 2023, 214: ID 119132.
|
| 36 |
LI Y T, FAN Q S, HUANG H S, et al. A modified YOLOv8 detection network for UAV aerial image recognition[J]. Drones, 2023, 7(5): ID 304.
|
| 37 |
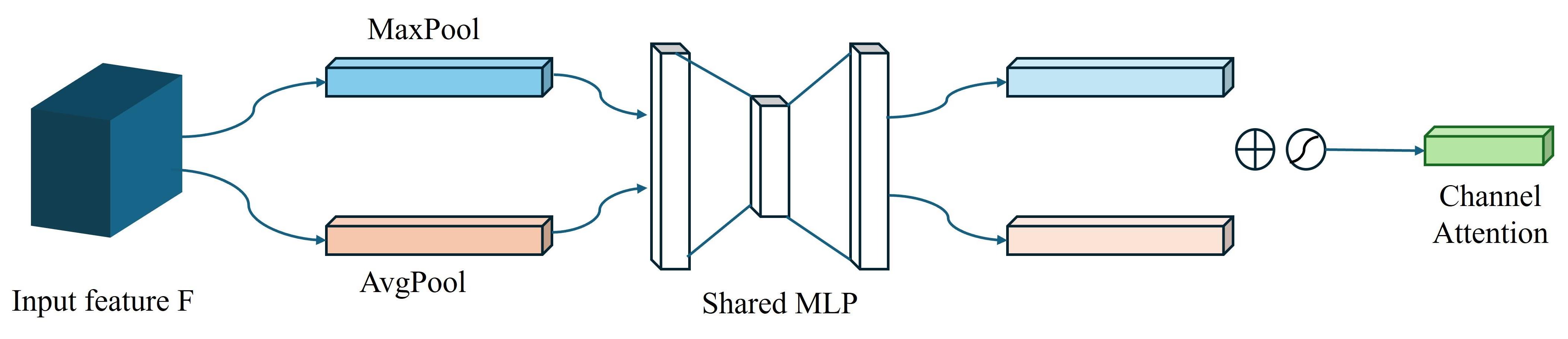
WOO S, PARK J, LEE J Y, et al. CBAM: Convolutional block attention module[M]// Lecture Notes in Computer Science. Cham: Springer International Publishing, 2018: 3-19.
|
| 38 |
HOU Q B, ZHOU D Q, FENG J S. Coordinate attention for efficient mobile network design[C]// 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway, New Jersey, USA: IEEE, 2021.
|
| 39 |
WANG J Q, CHEN K, XU R, et al. CARAFE: Content-aware ReAssembly of FEatures[C]// 2019 IEEE/CVF International Conference on Computer Vision (ICCV). Piscataway, New Jersey, USA: IEEE, 2019.
|
| 40 |
LI M Y, HUANG J Q, XUE L, et al. A guidance system for robotic welding based on an improved YOLOv5 algorithm with a RealSense depth camera[J]. Scientific reports, 2023, 13(1): ID 21299.
|
| 41 |
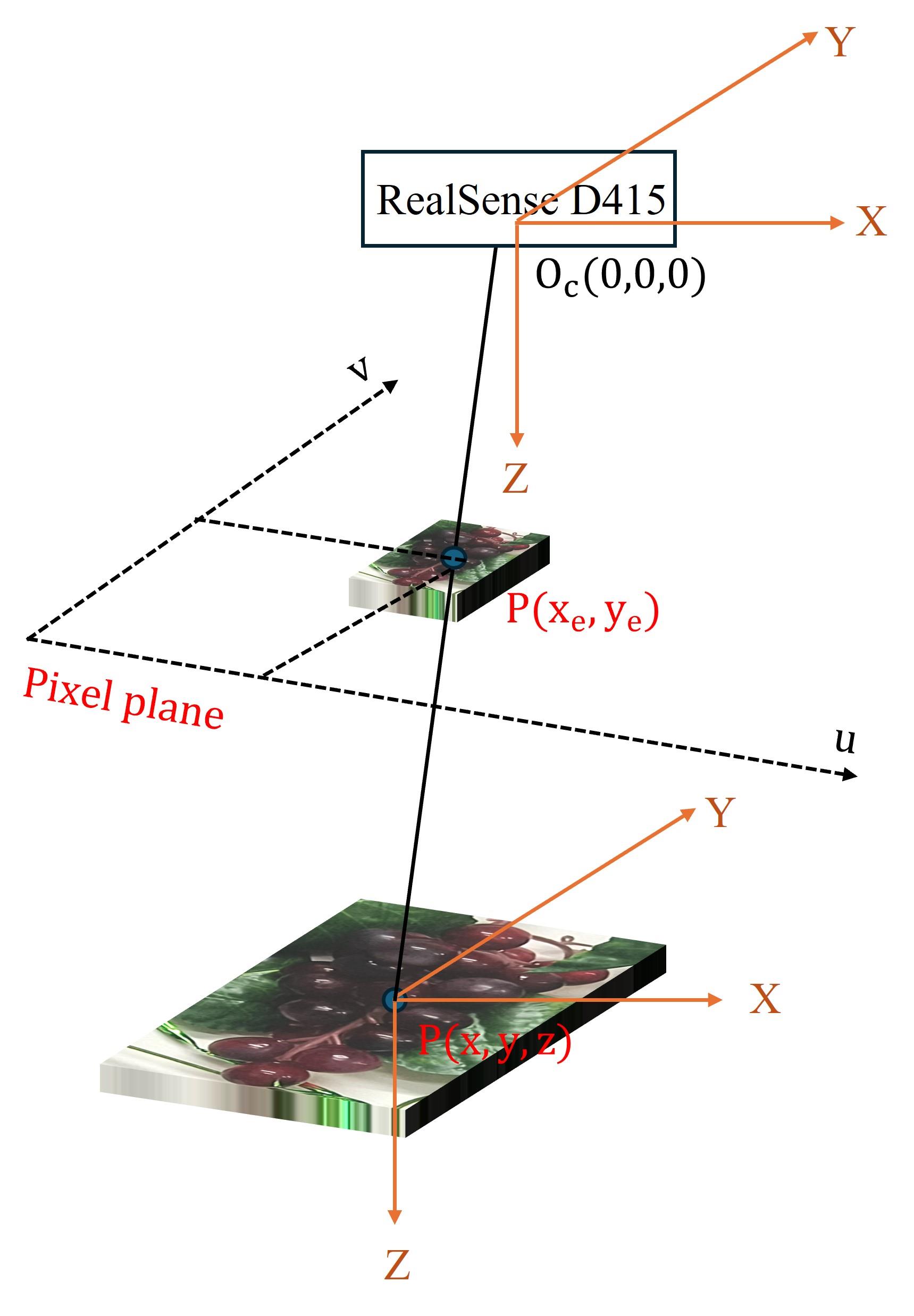
RegnierNicolaas. Grape bunch detect and segment[DS/OL]. [2024-05-11].
|
 ), 孙雨, 杨晶, 王凤超(
), 孙雨, 杨晶, 王凤超(